搜索指标调研
参考: https://zhuanlan.zhihu.com/p/447308381
https://www.8848seo.cn/article-5995-1.html
https://3g.163.com/dy/article/HE0IN6KM0511805E.html
https://www.zhihu.com/question/19624746
https://www.infoq.cn/article/cyw-evaluate-seachengine-result-quality/
https://www.infoq.cn/article/cyw-evaluate-seachengine-result-quality/
https://zhuanlan.zhihu.com/p/30910760
https://meitianjinbu.cn/sousuozhiliangpinggu.html
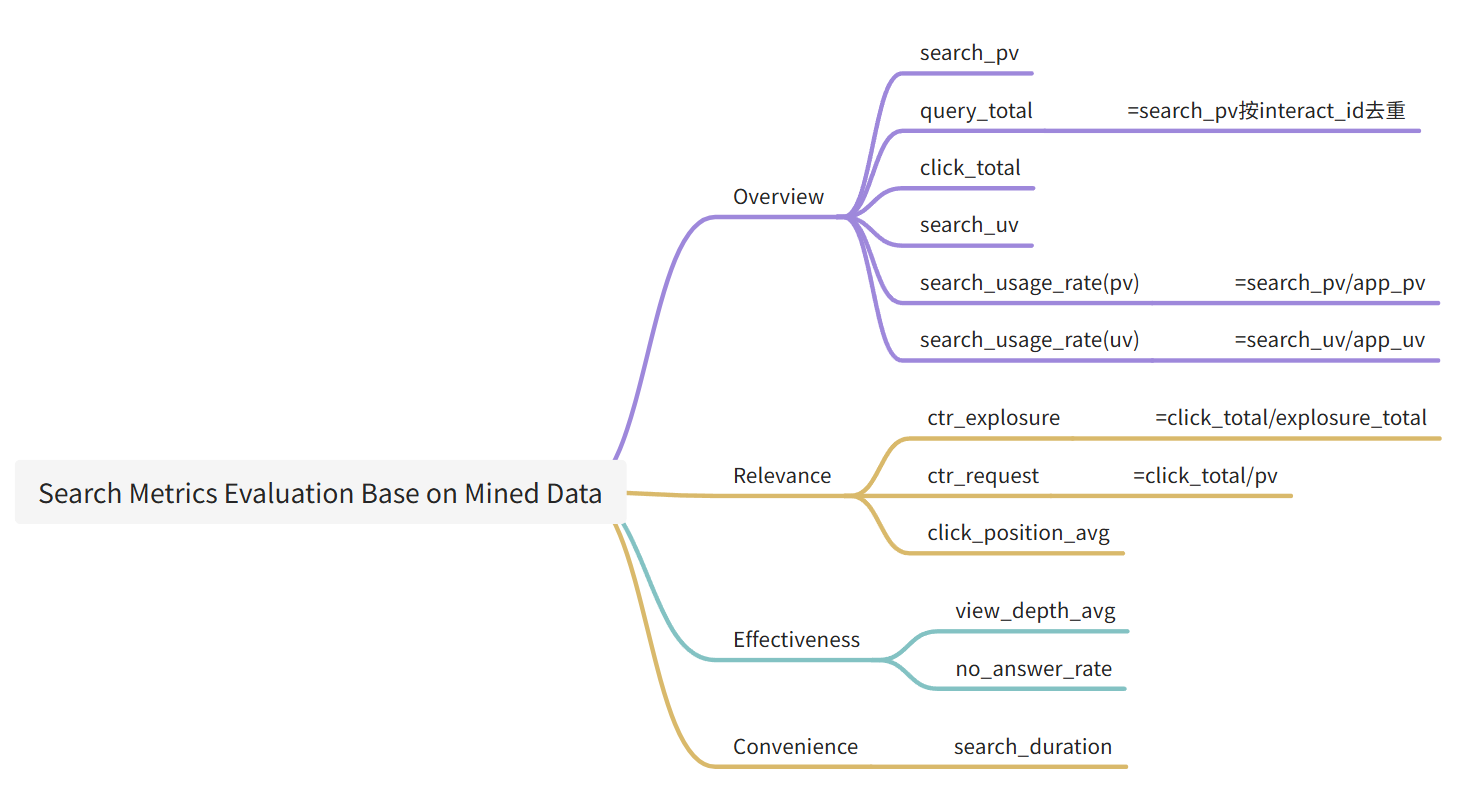
现有指标: 请求量, 请求用户数/占比, 主动搜索/占比, 点击次数, 点击率, 平均点击位置, 未应答覆盖率
七个维度
- 相关性: 搜索结果跟用户需求的匹配程度
- 需求比例: 越多人查找的需求越重要
- 丰富程度: 详细全面
- 有效性: 能否真正满足用户需求
- 时效性
- 便捷性: 找到目标要花多少时间和成本
- 权威性
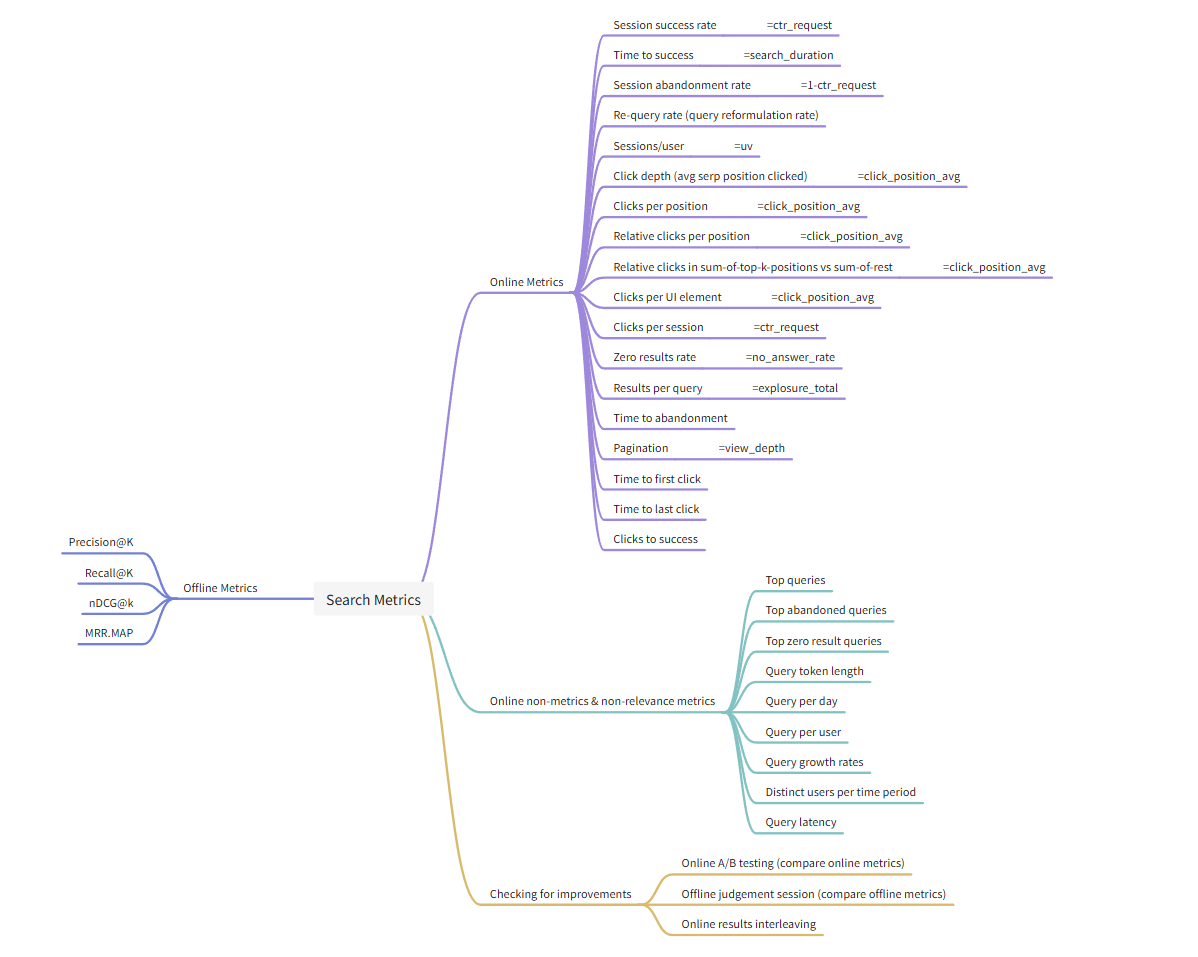
离线/在线
离线指标
- 排序评估(NDCG)刻画相关性
- 构造一套理想化的搜索结果(IDCG), 然后观察当前搜索结果达到理想态的分数, 如中文搜索以百度作为IDCG, 评比达到百度的多少分
- DCG(Discounted Cumulative Gain), 自己和自己比, 达到8分基本就是非常好的搜索引擎
- 人工评估(GSB)刻画相关性
- 指定严格的评判标准, 其中相关性遵循档位评估(prefect match, topic match, term match, no match)
- 实际迭代时, 采用严格的人工标注流程, 通过对相关性, 权威性, 质量, 时效, 多样等维度打出区分区
在线指标
- DAU(Daily Active User), 日活跃用户数量, (MAU, 月活)
- PV(Page View), 页面浏览量, 搜索核心业务指标
- 有点比(点击query/所有query), 一定程度反应出线上相关性
- 换query率, 一定程序反应相关性, 但也有可能结果很差, 用户不再搜索
- 首次点击位置, 一定程度反应相关性
- 浏览深度, 需结合其他指标, 若换query正向, 消费指标也正向, 浏览深度反而能帮助提升用户感知, 更好的消费, 若换query变多, 消费指标一般, 而浏览深度增加, 说明整体满足用户搜索需求做的不好
- 消费指标, 如点击率, 停留时长, 完播率, 点赞率等
流量/用户/策略
流量类指标
- 搜索DAU
- 搜索总时长
- 搜索次数, request/session
- 搜索分发量
- 搜索PV
- 搜索UV
用户类指标
- 人均搜索时长
- 人均搜索PV
- 人均搜索次数
- 搜索新增用户数
- 搜索新增次留率
- 搜索活跃次留率
策略类指标
- 搜索到达率
- 搜索召回率
- 搜索换query
- 搜索有点
- 搜索步长
- 搜索点展比
CTR/CVR/GMV
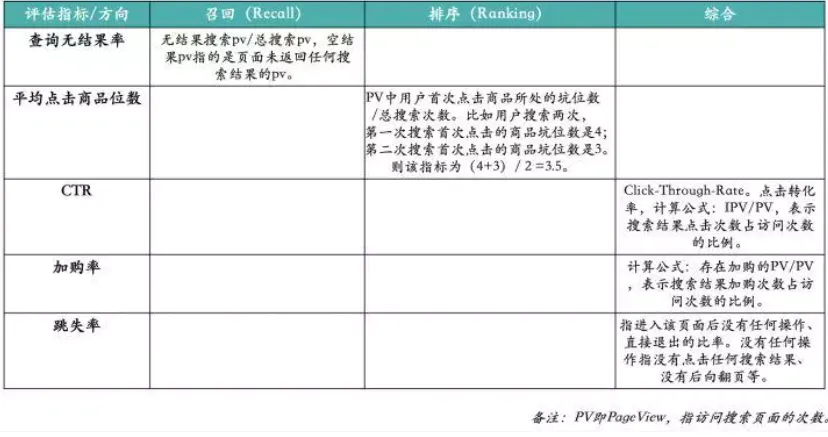
CTR

- 请求&用户维度的CTR极端情况会大于100%, 实际业务通常不会超过
- 曝光口径: 电商平台在5%左右, 对于搜索无结果的, 分子分母都为0, 不能反映实际情况; 且对于极端情况, 某一个搜索引擎搜索结果用户更感兴趣, 用户浏览和点击都更多, 但CTR不一定更高, 如A浏览5, 点击1, B浏览20点击3, A的CTR高, 但用户对B更感兴趣
- 请求口径: 两个小问题, 分子为0; 分子分母都为1, 需看点击次数
- session口径用的不多, 实际电商平台主要以曝光+请求维度CTR综合评估搜索引擎的线上用户点击效果
CVR

- 业务部门只关心曝光&请求口径的, 电商平台搜索引擎曝光口径的CVR一般在千分之几
- 算法部分一般使用点击口径CVR, 电商平台一般在2%-5%
PGMV(Gross Merchandise Volume)商品交易总额
Cranfield评价体系
- 抽取查询词组成规模适当的集合
- 从语料库检索寻找对应的结果, 进行人工标注
- 将查询词以及带有标注信息的语料库输入检索系统, 对检索结果进行计算评估与标注的理想结果的接近程度
Precision-recall(准确率-召回率方法)
- 通俗讲, 准确率就是算一算你查询得到的结果中有多少是靠谱的;而召回率表示所有靠谱的结果中,有多少被你给找回来了
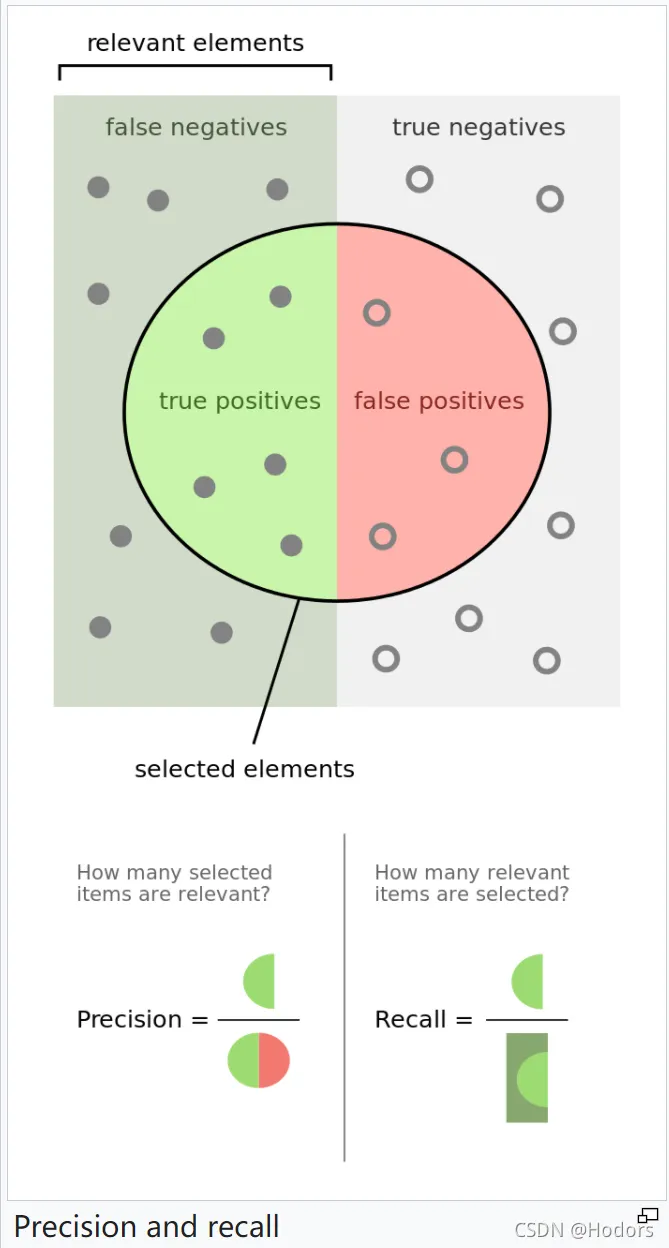
- Precision-Recall曲线
召回率与准确率会相互制约, 若期望召回更多, 必然要放宽检索标准, 导致不相关结果混入, 降低准确率; 若期望提高准确率, 必然要执行更严格的检索策略, 使召回率下降; PR曲线的总体趋势会如下
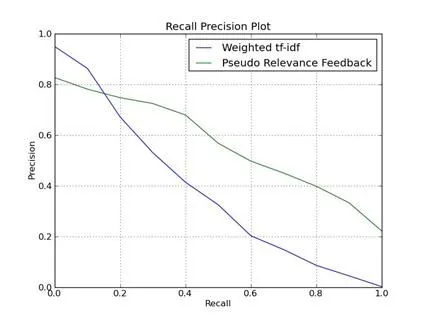
对于一些特定搜索应用会更关注结果中的错误, 如搜索引擎的反作弊系统会更关注作弊结果(假阳性), 对这些应用, 通常选用虚报率来统计
P@N, Precision@N, 指的是对特定的查询,考虑位置因素,检测前 N 条结果的准确率。例如对单次搜索的结果中前 5 篇,如果有 4 篇为相关文档,则 P@5 = 4/5 = 0.8 。一般取值为P@3或P@5, 对于寻址类, 一般为P@1
MRR
- MRR 是平均排序倒数(Mean Reciprocal Rank)的简称,MRR 方法主要用于寻址类检索(Navigational Search)或问答类检索(Question Answering),这些检索方法只需要一个相关文档,对召回率不敏感,而是更关注搜索引擎检索到的相关文档是否排在结果列表的前面。
- MRR 方法首先计算每一个查询的第一个相关文档位置的倒数,然后将所有倒数值求平均。
MAP
- MAP 方法是 Mean Average Precison,即平均准确率法的简称。其定义是求每个相关文档检索出后的准确率的平均值(即 Average Precision)的算术平均值(Mean)。这里对准确率求了两次平均,因此称为 Mean Average Precision。
- MAP 是反映系统在全部相关文档上性能的单值指标。系统检索出来的相关文档越靠前 (rank 越高),MAP 就应该越高。如果系统没有返回相关文档,则准确率默认为 0。
DCG(Discounted cumulative gain)
- 折扣增益值, 上文"离线指标"有提到, 核心思想是:
- 每条结果的相关性分等级来衡量
- 考虑结果所在的位置,位置越靠前的则重要程度越高
- 等级高(即好结果)的结果位置越靠前则值应该越高,否则给予惩罚
- nDGC(normalize DCG): 通过除以每一个查询的理想值 iDCG(ideal DCG)来进行归一, 求 nDCG 需要标定出理想情况的 iDCG
A/B Testing
A/B testing 系统在用户搜索时,由系统来自动决定用户的分组号(Bucket id),通过自动抽取流量导入不同分支,使得相应分组的用户看到的是不同产品版本(或不同搜索引擎)提供的结果。用户在不同版本产品下的行为将被记录下来,这些行为数据通过数据分析形成一系列指标,而通过这些指标的比较,最后就形成了各版本之间孰优孰劣的结论。
指标计算
- 基于专家评分, 根据预先设定的标准对 A、B 两套环境的结果给予评分,获取每个 Query 的结果对比,并根据 nDCG 等方法计算整体质量
- 基于点击统计, 使用了一个假设:同样的排序位置,点击数量多的结果质量优于点击数量少的结果, 在这个假设前提下,我们可以将 A/B 环境前 N 条结果的点击率自动映射为评分,通过统计大量的 Query 点击结果,可以获得可靠的评分对比。
Interleaving Testing
该方法设计了一个元搜索引擎,用户输入查询词后,将查询词在几个著名搜索引擎中的查询结果随机混合反馈给用户,并收集随后用户的结果点击行为信息.根据用户不同的点击倾向性,就可以判断搜索引擎返回结果的优劣
个人总结
现有埋点体系字段:
user_id, action, service, content_json
搜索的content_json:
List<String> show
String query
String click
Integer pageNo