计算架构模式
分布式缓存架构设计
参考: https://www.cnblogs.com/liconglong/p/16182277.html#_label4
数据缓存
简介: 用以解决读数据慢的问题, 缓存从库中读取的数据
- 应用场景: 实时性要求高的业务, 读多写少的场景, 如微博浏览
- 设计核心: 如何应对数据一致性的挑战?
- 数据缓存架构的一致性复杂度
- 【读】先读缓存, 没有再读存储系统
- 【写】
- 先写缓存后写存储(不建议), 写缓存成功写存储失败会导致数据异常, 关联业务异常
- 先写存储后写缓存(一般采用), 写存储成功写缓存失败会导致业务读取的旧数据直至缓存失效
- 先删缓存再写存储(适合用户相关数据), 正常情况下能保证数据一致性, 但缓存系统异常时, 为了不影响存储系统, 还需继续写入, 依然会导致不一致; 此外, 高并发时, 在删完缓存还没来得及写存储时有另一线程进行读操作, 依然可能导致旧数据写入缓存, 因此建议用户相关数据采用此种模式, 一般同一用户并发不会那么高
- 先删缓存再写存储再删缓存(适合全局数据, 如运营活动图片)
- 复杂度在于要跨越缓存和存储系统实现分布式事务
- 数据不一致性的解决方案
- 容忍不一致性, 设置缓存的有效期, 允许一定时期的数据不一致, 如新闻资讯, 微博, 商品信息等
- 关系数据库本地事务表, 先删缓存后写存储系统, 缓存异常时通过事务记录一条消息到本地消息表, 后台定时读消息表重试删除
- 消息队列异步删除, 总体同2, 但当缓存系统异常时发送消息到消息队列, 然后后台读消息队列重试删除
结果缓存
简介: 用以解决计算慢的问题, 缓存计算的结果
- 应用场景: 计算量大但实时性要求不高的场景, 如推荐, 热榜, 排行榜, 分页
- 设计核心: 如何平衡缓存有效期与结果新鲜度
缓存架构通用三类问题及设计
缓存穿透: 缓存里面没有数据
- 理想情况下, 缓存没有命中的比例达到90%, 甚至95%, 才能算作缓存穿透(因为正常逻辑也先读缓存, 没有数据再读存储系统)
- 要是缓存命中率低于80%, 则要进行分析, 可能是缓存使用有问题, 缓存的有效期设置有问题或缓存系统内存不足等
- 缓存穿透的场景
- 存储系统中确实不存在被访问的数据, 如被黑客攻击, 导致大量无效业务请求
- 存储中存在, 但缓存中不存在的数据, 如冷门数据, 老数据, 常见场景是爬虫, 或用户翻到20页以后导致系统变慢
- 系统刚启动, 缓存未生成, 如抢购, 秒杀, 或缓存节点刚启动
- 缓存集中失效, 如批量生成的缓存批量失效, 缓存服务器挂掉
- 常见缓存穿透应对方法
- 空值缓存, 应对被攻击或被爬虫试探, 当读缓存以及存储系统都失败时, 可缓存一个过期时间较短的null值
- 缓存当前数据, 应对爬虫或用户翻到中部尾部, 只缓存当前数据存储系统, 对历史数据不做处理
- 缓存预热, 应对运营活动, 秒杀, 大促等场景
- 模拟请求触发系统生成缓存, 实现复杂
- 后台按规则批量生成缓存, 工作量大
- 灰度/预发布触发系统生成缓存(推荐)
- 随机失效, 应对后台批量生成的缓存, 缓存有效期设定一个时间范围内的随机值
缓存雪崩: 缓存失效引起雪崩效应
- 当缓存失效(过期)后发生连锁反应, 引起系统性能急剧下降的情况, 连锁反应指的是大量并发读请求落到存储系统或计算系统上, 导致系统无法响应
- 与缓存穿透的区别
- 缓存穿透需要大量请求比如几万个请求才能把系统搞崩, 但缓存雪崩可以是一个请求比如计算排行榜直接把系统搞崩
- 举例第一个计算排行榜的请求, 缓存失效, 后续有50个并发请求排行榜, 都会直接访问计算系统, 导致慢任务累加, 最终连锁导致缓存雪崩
- 缓存雪崩应对方法
- 更新锁, 保证只有一个线程能够更新缓存, 未获取到锁的线程要么等待锁释放重新读, 要么返回空值默认值
- 后台更新, 由后台线程如定时任务, 或事件触发来更新缓存, 业务线程仅读取缓存, 不存在则返回空值
缓存热点: 部分缓存访问量超高
- 特别热点的数据访问量超高, 导致缓存服务器扛不住, 如明星热点事件
- 缓存热点应对方法
- 多副本缓存, 写入时给缓存的key加上编号, 写入多个缓存服务器, 读取时随机生成编号组装key, 然后读取, 问题在于不好预料哪些key是热点, 需要动态决策或人工干预
接口高可用
- 雪崩效应: 请求量超过系统处理能力后导致系统性能螺旋快速下降
- 链式效应: 某个故障引起后续一连串的故障
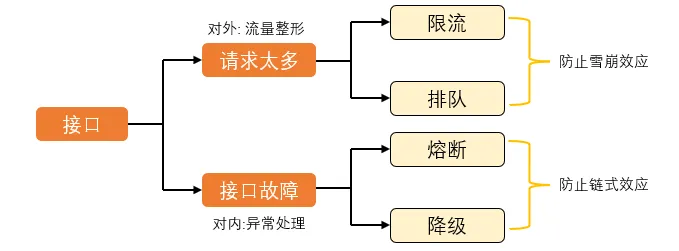
限流
用户请求全流程各个环节都可以限流
- 请求端限流: 发送请求时限流
- 限制请求次数, 如按钮变灰
- 嵌入简单业务逻辑, 如抢红包, 客户端生成随机数未落入指定区间直接失败, 请求不会到达后端
- 接入端限流: 接受业务请求时限流
- 限制同一用户请求频率
- 随机抛弃无状态请求, 如限制浏览的, 不限制下单的(保证下单可用)
- 微服务限流: 单个服务自我保护机制
- 请求端限流: 发送请求时限流
限流算法
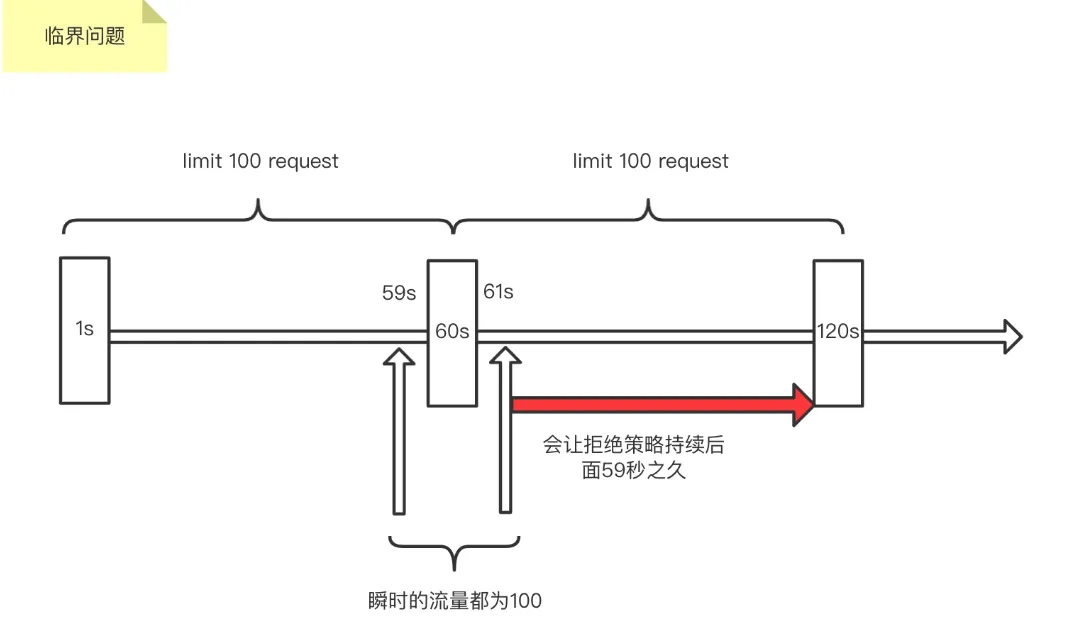
- 固定时间窗, 统计固定时间范围内的请求量, 超过阈值则限流(随机丢弃或丢弃无状态请求), 但存在临界点问题如下图, 刚好在两个时间窗之间有瞬时流量超过阈值
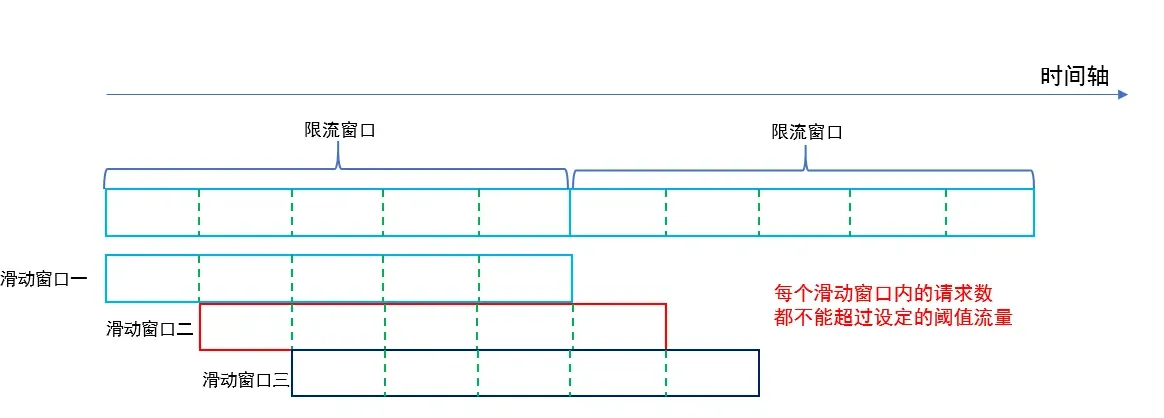
- 滑动时间窗, 统计滑动时间周期内的请求量, 超过阈值则限流, 能解决固定时间窗的问题, 但实现更复杂
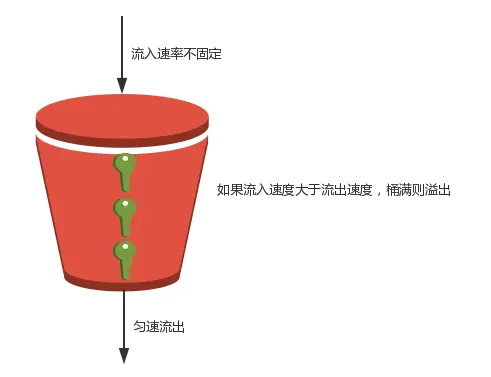
- 漏桶, 将请求放入桶(消息队列等), 业务处理单元从桶里拿请求进行处理, 桶满则丢弃新的请求, **技术本质是总量控制**, 桶大小是设计关键, 缺点是桶大小动态调整比较麻烦, 一般需要应用重启, 一般应用在瞬时高并发流量, 如0点签到, 整点秒杀等场景
- 令牌桶, 某个处理单元(比如定时线程)按照指令速率将令牌放入桶中, 业务处理单元收到请求后需要先获取令牌, 获取不到则丢弃请求, 技术本质是速率控制, 令牌产生的速度是设计关键, 可以动态调整处理的速度, 但在突发流量时可能丢弃很多请求, 一般应用在控制访问第三方服务的速度, 以及控制自身的处理速度, 防止过载等场景 (注意桶不能设计的很大, 不然突然流量获取大量令牌可能直接把服务压垮)
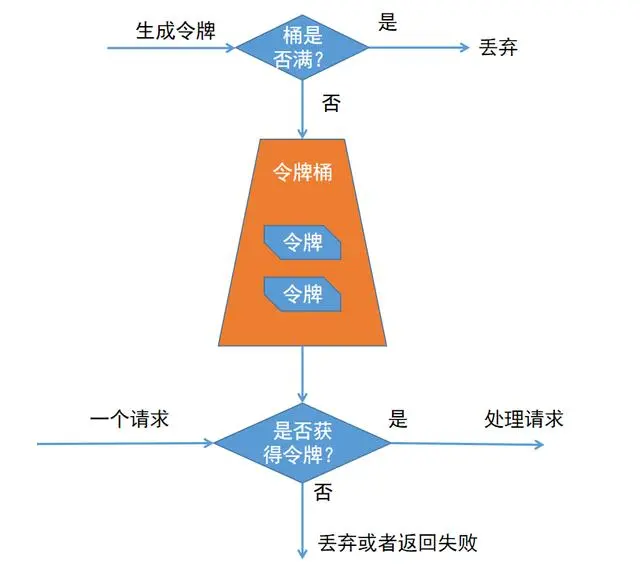
令牌桶一般适用于短时间如1s, 2s的突发流量, 为了避免把系统压垮, 会丢弃大量请求
而漏洞一般使用于持续时间较长如1min, 2min, 期间系统会达到最大的处理速度尽量处理用户请求, 因此适用于秒杀, 整点签到等场景
排队
- 基本原理是收到请求后并不同步处理, 而是将请求放入队列, 系统根据能力异步处理
- 技术本质是请求缓存 + 同步改异步 + 请求端轮询
- 应用场景有秒杀, 抢购等
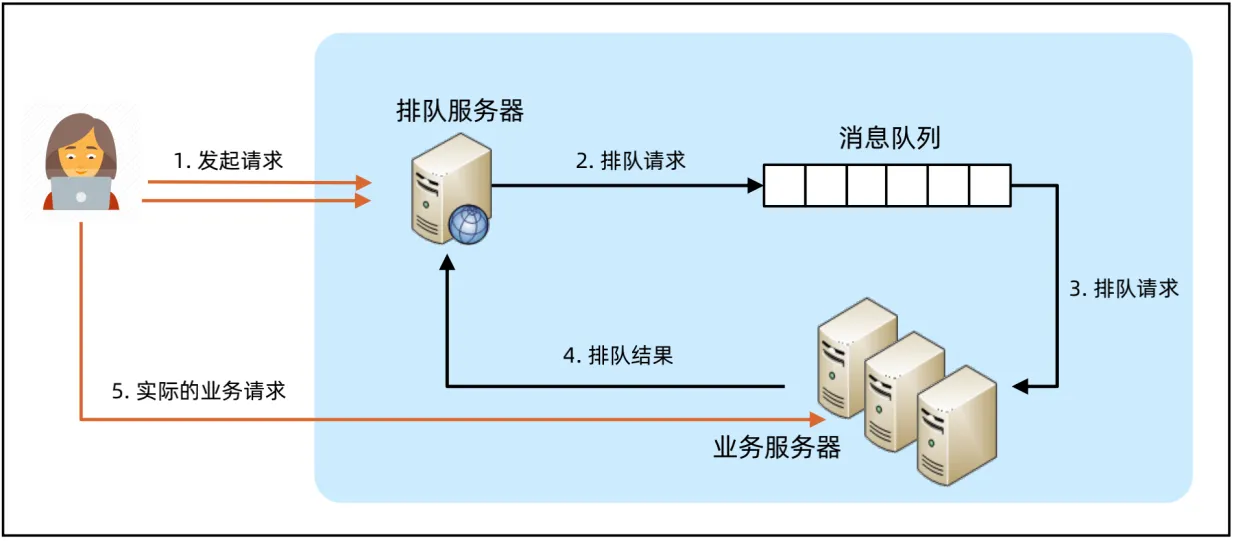
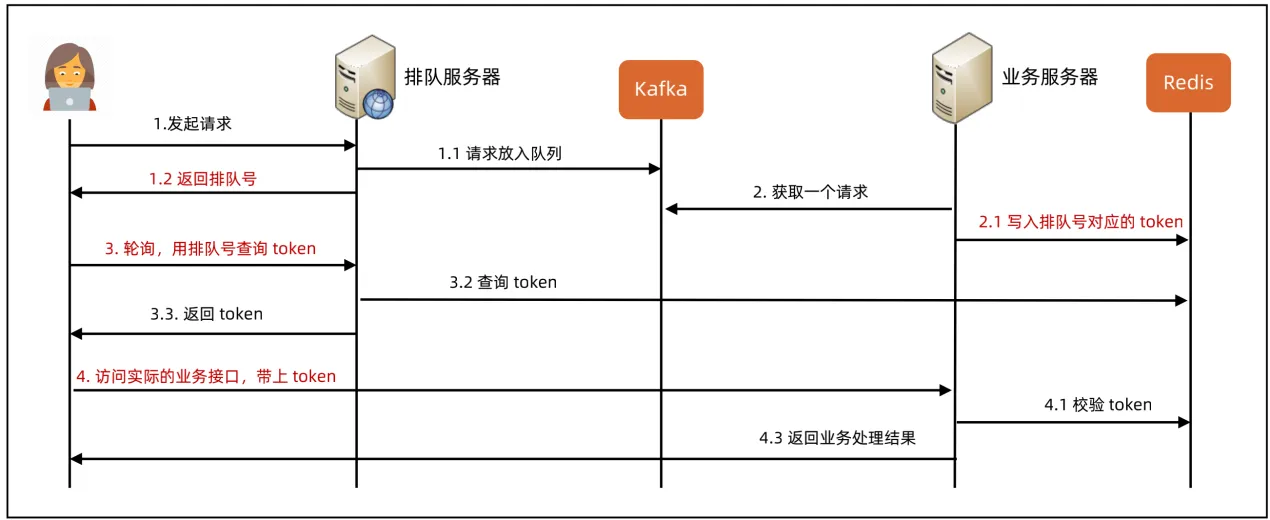
- 排队的设计关键是如何设计异步处理流程,如何保证用户体验(前端、客户端交互), 如下异步流程中的token是为了防止伪造请求(拿排队号直接刷), 排队号是为了权衡用户体验, 告知用户前面还有多少人
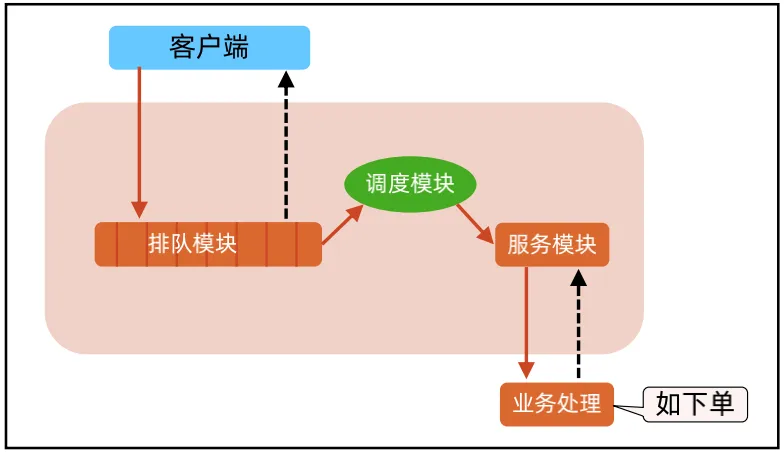
- 如1号店双十一排队案例, 多了个调度模块负责排队模块和服务模块的动态调整

降级
- 降级是直接停用某个接口或URL, 收到请求后直接返回错误如HTTP 503, 主要用于故障应急, 通常会把非核心业务降级, 保住核心业务, 如降级日志服务等
- 常见的降级架构: 运维或管理人员发送降级指令, 运维系统的降级模块通知接入服务器降级
熔断
- 下游系统故障的时候, 一定时期内不再调用, 主要用于服务的自我保护, 防止故障链式效应
- 熔断一般由框架或者SDK提供, 如Dubbo, Hystrix等, 熔断策略一般按照失败次数, 失败比例, 响应时长来确定