如何设计存储架构
参考:https://www.cnblogs.com/liconglong/p/16156453.html#_label1
存储架构设计总的思路
1.估算性能需求
- 基于具体的业务场景来估算性能需求, 包括存储量, 读写性能等
- 用户量预估-->用户行为建模-->性能需求计算
- 用户量估算:可以通过规划、推算、对比的方式进行估算
- 规划:根据成本、预算、目标等去确定规划,例如某个新业务预算投入2000W进行拉新,首先我们要对行业有一定的了解,在互联网,一般情况下拉新一个安卓用户是100块钱,一个IOS用户是140块钱。那么就可以用成本的2000W计算可以拉新多少用户。再或者年底某业务用户规模达到100W,那么无论这个结论是否是在画饼,那么我们都应该按照100W去预估。
- 推算:基于已有数据进行推算,例如做一个面向一个城市的在校大学生购物小程序,首先要查询一下该城市的在校大学生有多少,在预估一下在校大学生有多少会用这个购物小程序,基本上就可以推算出用户量;再例如香港地铁扫码乘车业务,首先查一下香港的总人数,然后在预估一下乘地铁的人数,例如有80%,那么用总人数乘以80%即可得到用户量。
- 对比:假设做一个新业务,既不知道规划又没办法推算,但是业界已经有竞争对手或者标杆了,那就可以跟已有标杆对比,例如已经有了拼多多,淘宝要做一个淘宝特价版,要预估一下用户量,这个就可以对比一下拼多多的用户量,然后基于一定的比例,计算出自己的用户量;还有就是可以跟自己已有的同类业务对比,例如美团做酒店的业务预估用户量,就可以拿着美团的机票业务用户量进行预估。
- 用户行为建模: 可以从行为、数量、频率三个维度进行评估,行为是指用户的典型行为,数量是指采取某种行为的用户数量,频率是指用户某种行为的频率。例如,预计每个月使用钱包付款码的用户由100W,付款笔数达到500W笔;再或者每天使用扫码乘车的用户有500W,平均扫码次数4.6次.
- 存储性能需求计算:可以通过数据量、请求量、预留量三个维度进行评估,存储量指需要存储的数据总量,请求量是指对数据的读写请求(QPS/TPS),预留量指的是需要预留出来的增长空间。
- 并不是所有的数据都一定要同样的存储方式,例如当前数据和历史数据需要分开存储;
- TPS/QPS需要计算出以秒为单位的数值,并且要计算平均值和峰值;
- 预留增长不能太大也不能太小,太大太小没有固定标准,一般1.5倍、2倍都是可以的,但是不能是1.1倍,100倍这种,如果能做到线性伸缩是最好的。
案例:
用户行为建模:每天使用扫码乘车的用户有500W,平均扫码次数4.6次。
分析和计算过程:
(1)假设总用户量为1000W,则用户存储量是1000W
(2)每次扫码乘车,都会访问一次用户数据,则用户数据读取次数:每天 500W * 4.6 = 2300W
(3)每次扫码乘车都会生成一条乘车记录,则单日乘车记录: 500W * 4.6 = 2300W
(4)乘车记录要保存两年,则总数据量为:2300W * 800 = 200亿
(5)每条乘车记录对应一条支付记录,单日支付记录为2300W,总数据量为200亿
(6)地铁乘车60%集中在早晚高峰的两个小时中,因此乘车记录写入的TPS峰值为 2300W * 60% / (2 * 3600) = 2000
如果这个单指香港地铁的系统,那么就不需要预留空间了,因为香港总人数为七八百万,这里已经预估用户量为1000W了,已经足够大了,因此不再需要预留空间
2.选择存储系统
根据技术储备, 方案优缺点选择合适的存储系统
- 先选架构模式
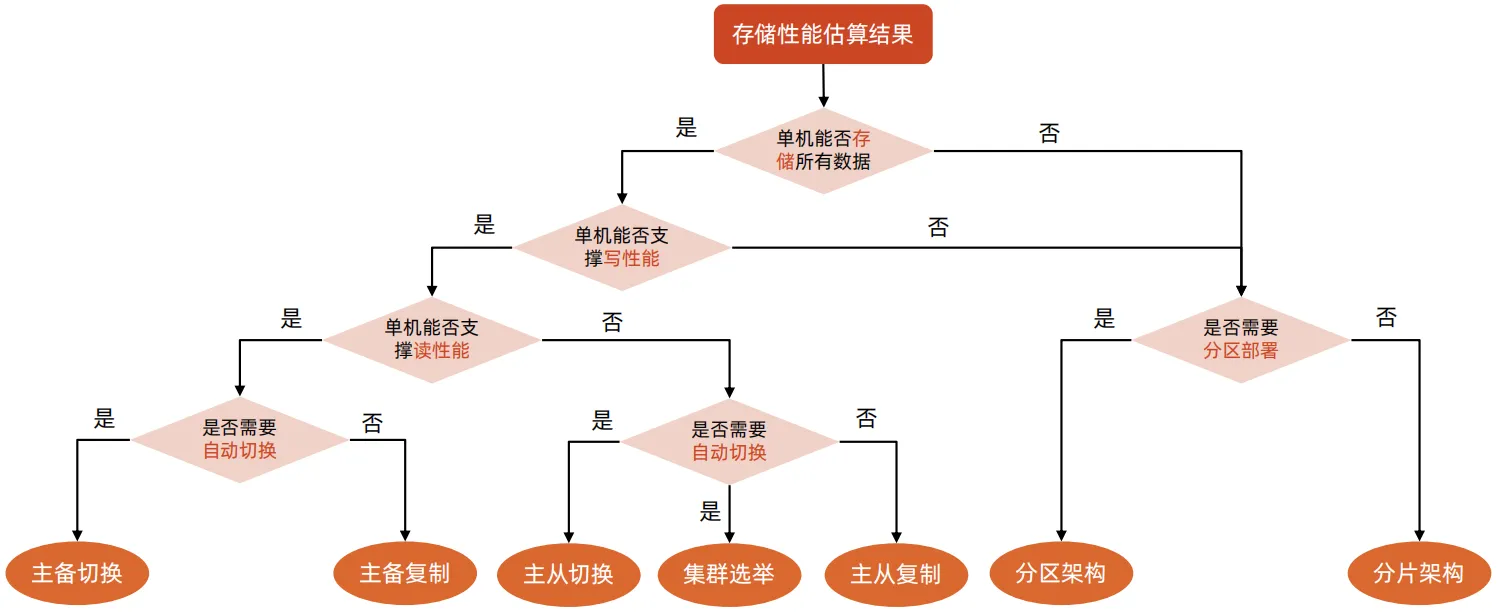
再选存储系统
- 先看技术本质: 挑选应用场景和系统本质切合的系统, 比如MongoDB是文档数据库, MYSQL是关系数据库Redis是Remote dictionary Server, Es是倒排索引搜索引擎, HBase是"sparse, distributed, multidimensional sorted map"等
- 再看技术储备: 挑选熟悉的
- 再从可维护性, 成本, 成熟度等综合考虑
常见的存储系统
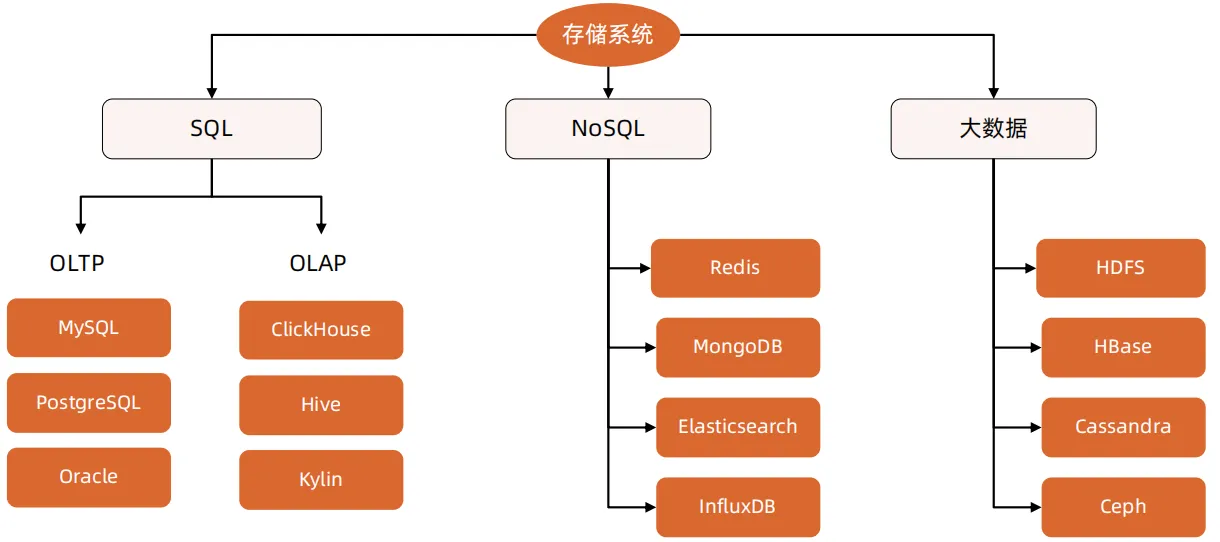
3.设计存储方案
- 基于选择的存储系统, 设计其具体的存储方案, 如果不行, 回到步骤2再换一个, 存储方案的设计要具体到数据结构的设计, 例如如何设计具体的表,选择Redis的哪个数据结构
- 步骤:
- 设计数据结构:基于选择的存储系统提供的数据结构,选择或设计具体的数据结构来实现我们的业务需求,例如如何设计具体的表,选择Redis的哪个数据结构
- 验证读写场景:将数据结构放到具体的场景进行验证,设计读写具体如何执行
- 评估读写性能:评估具体场景下的数据结构设计是否满足性能需求,不满足则重新设计。
案例:Redis存储粉丝列表,首先我们已经选择了Redis作为存储系统,然后有两种落地方案,一种是List,一种是Sorted Map。
设计数据结构:选择List,List是有序的,可以重复
验证读写场景:如果新增关注,需要扫描List判断是否重复,不重复则尾部增加;取消关注时,需要扫描List找到粉丝ID进行删除;拉黑和取消一样
评估读写性能:新增关注、取消关注都需要扫描整个List,特别是大V,性能会很低,某些爆红的账户可能存在性能问题,因此需要再迭代看看是否有其他更合适的方案。
设计数据结构:选择Sorted set,有序但不能重复
验证读写场景:新增关注,使用关注时的时间作为score来排序,无需扫描,Redis会自动去重;取消关注和拉黑时直接删除。
评估读写性能:无论是读写性能还是实现复杂度,都比List简单。
常见存储系统
学习一种技术,首先要理解技术本质、然后明确部署架构、再研究数据模型、最后模拟业务场景。
- 理解技术本质:理解系统核心的技术本质,技术本质决定了应用场景和性能量级。例如Redis是K-V存储系统,HBase是sorted map。
- 部署架构:学习存储系统支持的部署架构,明确其架构本质。例如Redis可以使用单机、主从、哨兵、集群四种部署架构;HBase只有一种部署架构。
- 研究数据模型:研究存储系统提供的存储模型,包含哪些概念,如何应用等。例如Redis支持多种数据类型,HBase的table、column等
- 模拟业务场景:模拟一些常见的业务场景,完整实现一个案例,并测试其性能,也可以先参考网上已有的测试结论。例如如何用Redis来存储关注关系,如何用HBase存储关注关系等。
Redis
- 技术本质:基于内存和数据结构存储,基于内存意味着高性能,但也意味着持久化不是其核心,可能会造成数据丢失,数据结构存储表示其不是关系型数据库,也不是文件存储
- 用途:数据库、缓存、消息服务器
- 性能量级:TPS 5~10 万
- Redis部署架构:有主从、哨兵、集群三种方式,主从的技术本质是主从复制、读写分离,但是无自动切换功能;哨兵的技术本质也是主从复制、读写分离,但是器可以自动切换;集群的技术本质是数据分片。
- Redis的数据结构:String、List、Hash、Set、Sorted set
- 模拟业务场景:用Redis实现关注列表存储,使用List和使用Sorted set,具体分析上面已经说过。
HBase
- 技术本质:no-relational:非关系型数据;versioned:多版本的;after Bigtable:基于谷歌的Bigtable 原理实现的(Bigtable 的原理:multidimensional sorted map,实际上就是按照key排序的map,map里面有字段有值,就相当于一个字段);on top of Hadoop and HDFS:基于 Hadoop 和 HDFS来搭建的,底层存储结构是 LSM。
- 用途:大数据存储,那多大的数据才算大数据呢,一般从数据量级上来说,10亿条以上才算大数据;从数据容量上来说,最起码得几T才是大数据
- 参考性能量级:四台32核主机每秒插入70000条,读取大约是25000条,扫描100条以内记录,每条15000条。这里可以看到写入和必读取快,这是因为HBase底层存储结构是LSM,是基于日志合并的,写入的时候,只需要尾部追加即可,而读取时,需要合并多条日志,因为可能同一个日志写了多次,因此需要合并日志。
- 部署架构:本质上是分片集群,Zookeeper做HMaster的切换,RegionServer由HMaster管理。
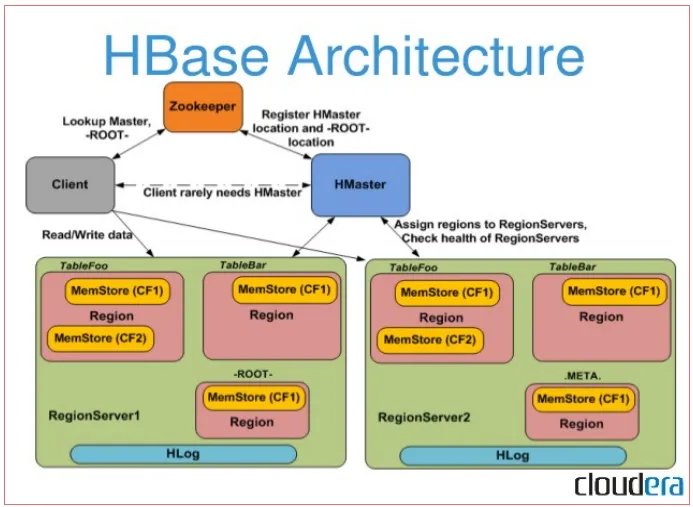
- 数据结构:table-表;row-行;column family-列簇,指多个列合并在一起;Column-列;Cell - 一个具体的存储单元;Timestamp - 多版本,一个数据写入多份,可以根据Timestamp区分多版本。
- 模拟业务场景: 略
HDFS
- 技术本质:基于Google的GFS论文的开源实现。file system :这是文件存储,不是关系数据,也不是数据结构。distributed:分布式的文件存储,不是类似于 Linux 的 Ext 文件系统。low-cost hardware:运行在低成本硬件,而不是 IOE 的高成本硬件。
- 用途:arge data sets:大数据存储,可以横向伸缩,瓶颈是网络的带宽。
- 参考性能量级:性能可横向伸缩,瓶颈是带宽。
- 部署架构:分片集群,大文件存储,不适合只存储只有几K的小文件,使用Zookeeper来做高可用,用Namenode来做集群管理。
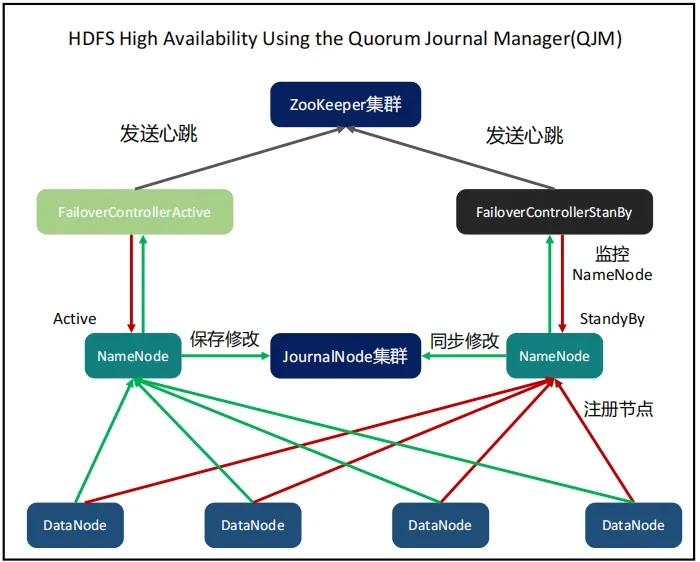
- 数据模型:简单来说,这就是一个文件系统,你需要自己来规划好目录和文件就可以了,意味着从传统的磁盘文件存储迁移到HDFS存储是非常方便的。
Clickhouse
- 技术本质:列式存储,数据库管理系统,OLAP 场景(OLAP,做数据分析用的,而不是做在线的业务访问用的;MySQL 是 OLTP)
- 用途:OLAP
- 相关知识:OLTP:联机事务处理,执行大量增删改查,关注响应速度、高并发、数据一致性。OLAP:联机分析处理,执行少量复杂查询,关注吞吐量,很少修改数据。行式存储:表中的一行记录存储在一个数据块中。列式存储:表中的一列数据存储在一个数据块中。
- 部署架构:分片集群、Zookeeper管理,分片独立复制
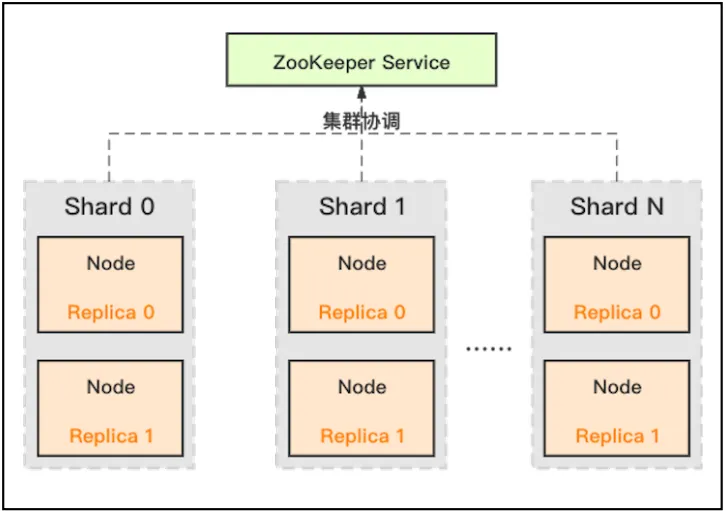
- 数据模型:基于 SQL 表设计即可。如果你需要将原来基于数据库的统计分析剥离出来,且数据量并不大的话,使用ClickHouse的复杂度是很低的;而如果切换为Hadoop、Spark这类平台的话,切换复杂度和成本就会高很多