工具与场景
性能测试工具功能
- 录制或编写脚本功能
- 参数化功能
- 关联功能
- 场景功能
- 报告生成功能
性能工具的脚本能力
录制
- 本地录制:通过截取并解析与服务器的交互协议包,生成脚本文件。比如说 LoadRunner 调起 IE 的时候,不用修改 IE 的代理设置,就可以直接抓取 HTTP 包,并通过自己的解析器解析成脚本。
- 代理录制:通过代理服务器设置,转发客户端和服务器的交互协议包,生成脚本文件。JMeter 中的脚本录制功能就是这样做的。
代理录制的逻辑
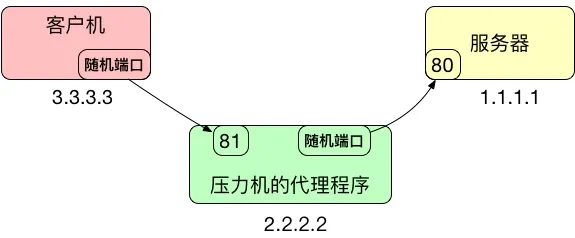
- 我们在 IP 为 2.2.2.2 上的主机上,打开一个代理程序,开 81 端口,所有到 81 端口的都转发到 1.1.1.1 的 80 端口。
- 当 3.3.3.3 主机要访问 1.1.1.1 的的 80 端口,可以通过访问 2.2.2.2 的 81 端口进行转发。
注意: 客户机不一定要和代理服务器在同一台机器上
关联与断言
关联的数据后续脚本中会用到,参数化则不会。断言倒是比较容易理解,就是做判断。
- 关联:常见的SessionID就是典型的需要关联的数据
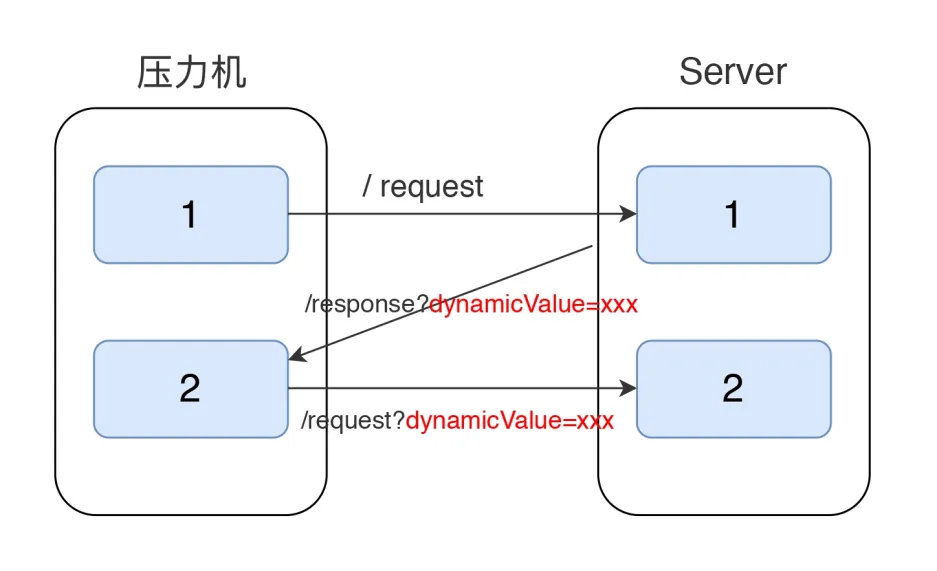
- 断言:就是用来判断服务端返回的结果对不对
JMeter使用
创建线程组
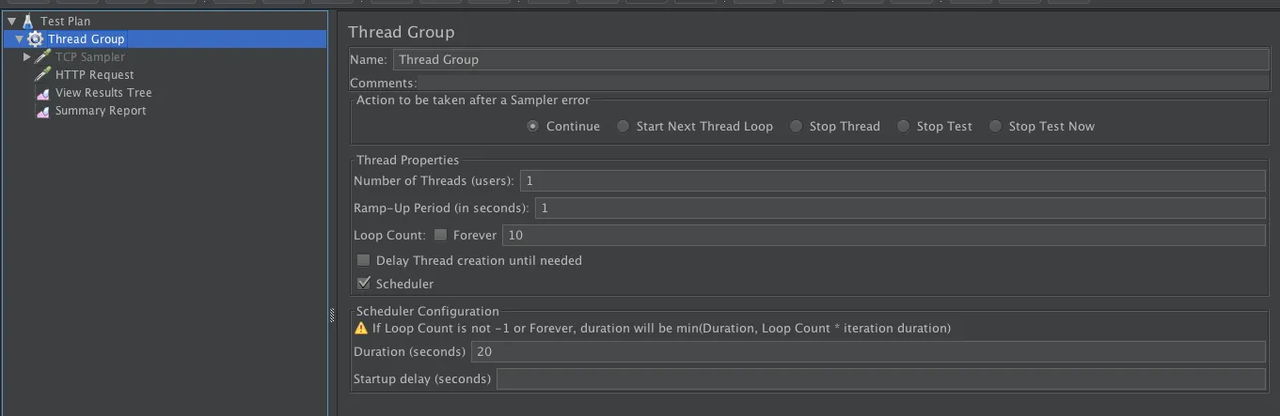
- Number of Threads(users): JMeter 中的线程数
- Ramp-up Period(in seconds):递增时间,以秒为单位。指的就是上面配置的线程数将在多长时间内会全部递增完
- Loop Count: 一个线程中脚本迭代的次数
- Delay Thread creation until needed:JMeter默认启动时创建所有线程, 这里可以设置在需要时创建, 由于创建线程时会挤占压力机的CPU, 一般不选
- Scheduler Configuration; If Loop Count is not -1 or Forever, duration will be min(Duration, Loop Count * iteration duration), 举例如果Loop Count设置为100, 响应时间为0.1s, duration设置为100s, 那么10*0.1=10s<100s, jmeter在运行10s后会停止
创建HTTP Sampler
- Content type默认为text, 需要加个Header设置为JSON

- 默认的charset=UTF-8, 不用特殊配置
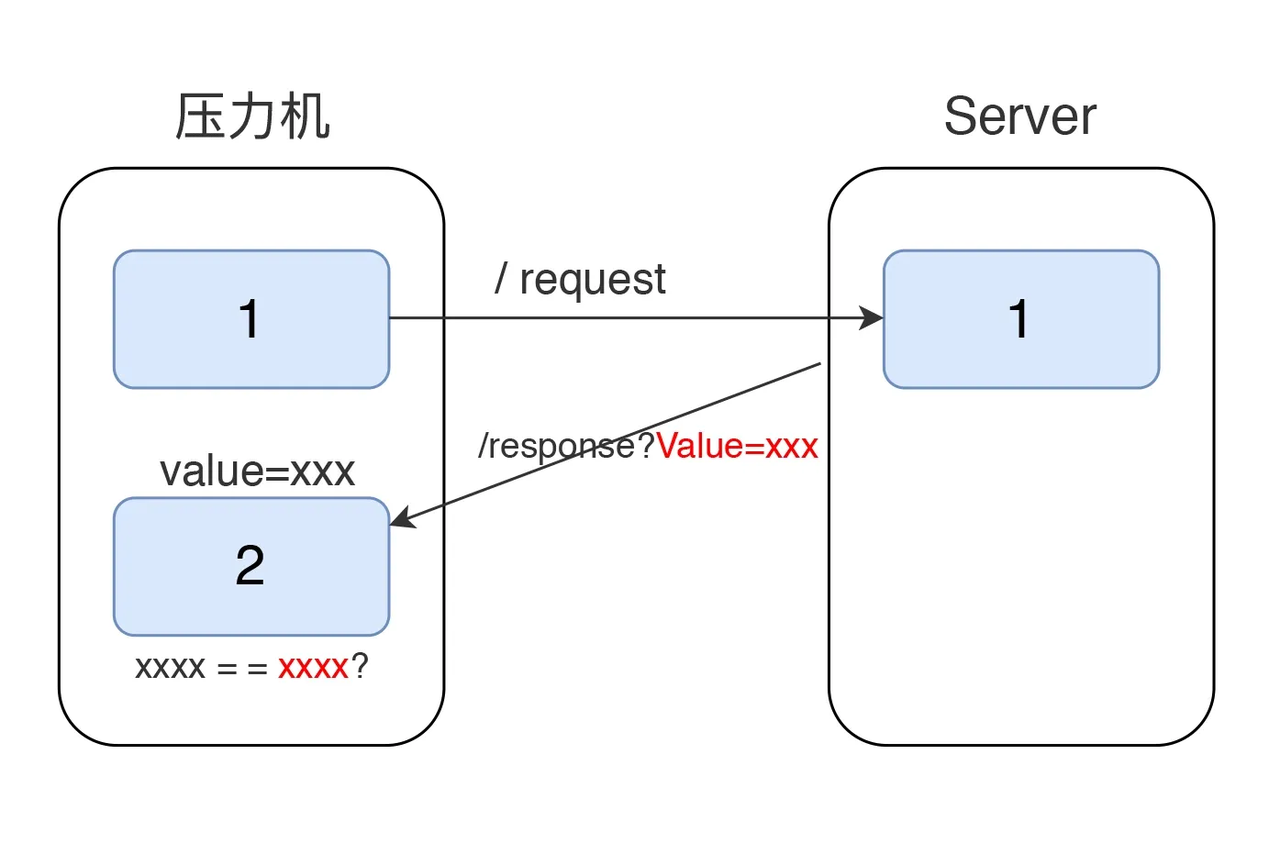
关联
以下使用关联处理HTTP Basic认证产生的CSRF问题
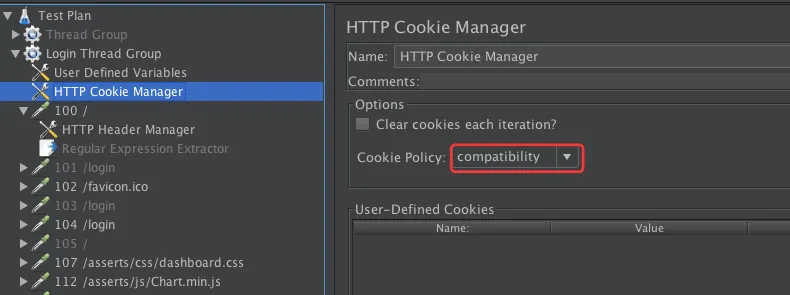
- 添加Cookies Manage
- Cookie Policy 一定要选择 compatibility,以兼容不同的 cookie 策略。
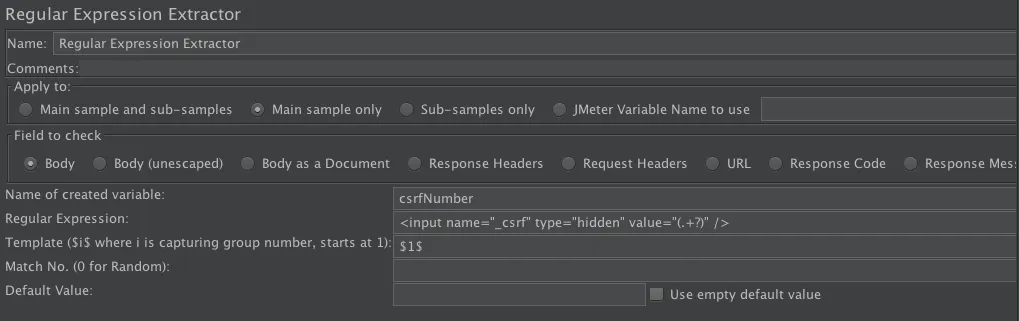
- 取动态值,在返回 CSRF 值的地方加一个正则表达式提取器来做关联
- 发送时的 CSRF 值替换成变量

补充:
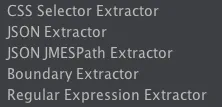
上面是用的正则提取器,在 JMeter 中,还有其他的提取器, 比如说如果你返回的是 JSON 格式,就可以使用上图中的 JSON Extractor。
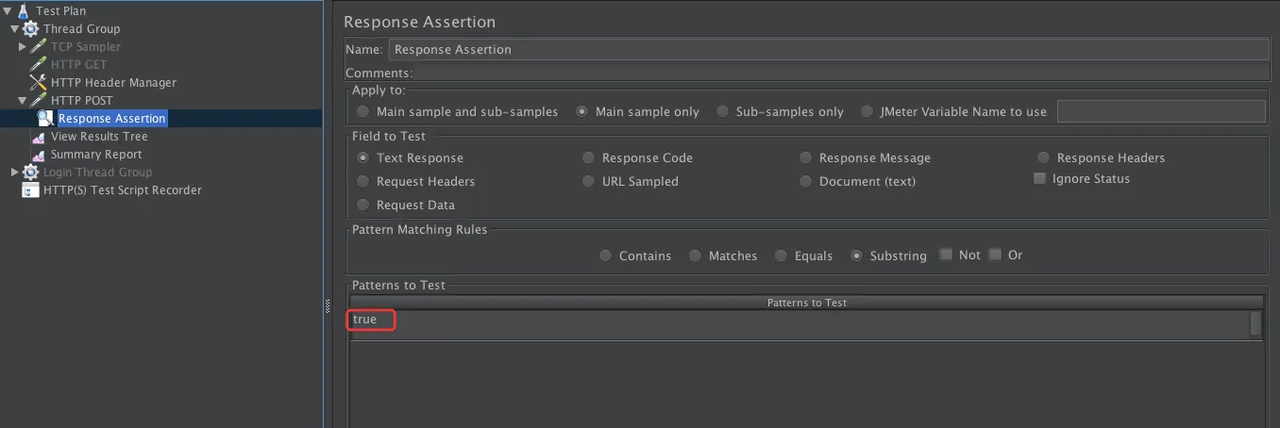
断言
参数化
先做基准测试, 确定需要多少真实的数据, 比如TPS=100, 那么压测5分钟需要 100560=30000条真实数据
- 设置 CSV Data Set Config
- Allow quoted data, 根据数据是否有引号设置为true或false
- Recycle on EOF, EOF表示end of file参数文件用完了, jmeter提供了三个选项, true, false, 以及edit, edit表示在没有参数的时候回根据定义的内容来调用函数或者变量
- Stop thread on EOF, 同上
- Sharing mode, 指定参数的生效范围, 有四个选项All threads、Current thread group、Current thread、Edit, edit表示自定义
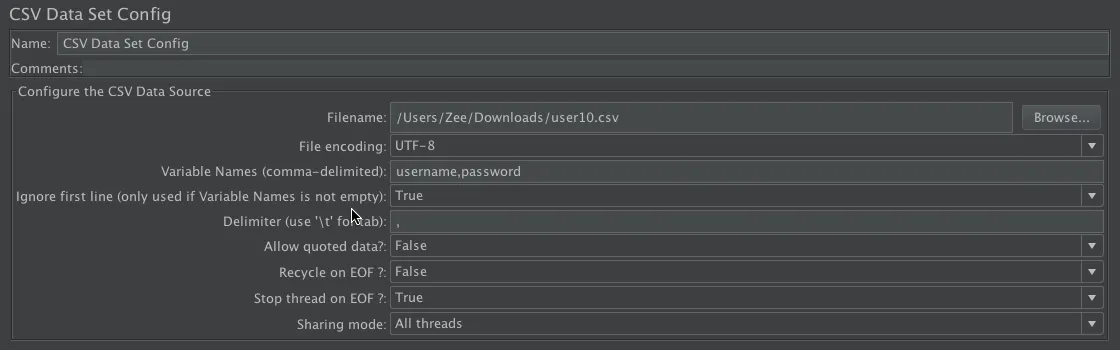
- 准备数据
Java
Java
username,password
test00001,test00001
test00002,test00002
test00003,test00003
test00004,test00004
test00005,test00005
test00006,test00006
test00007,test00007
...................
test30000,test30000总结
- 分析业务场景;
- 罗列出需要参数化的数据及相对应的关系;
- 将参数化数据从数据库中取出或设计对应的生成规则;
- 合理地将参数化数据保存在不同的文件中;
- 在压力工具中设置相应的参数组合关系,以便实现模拟真实场景。
参数化数据
数据量
参数化数据要用到多少取决于场景,举例来说,对一个压力工具线程数为 100,TPS 有 1000 的系统,如果要运行 30 分钟,则应该取得的参数化数据是下面这样的。
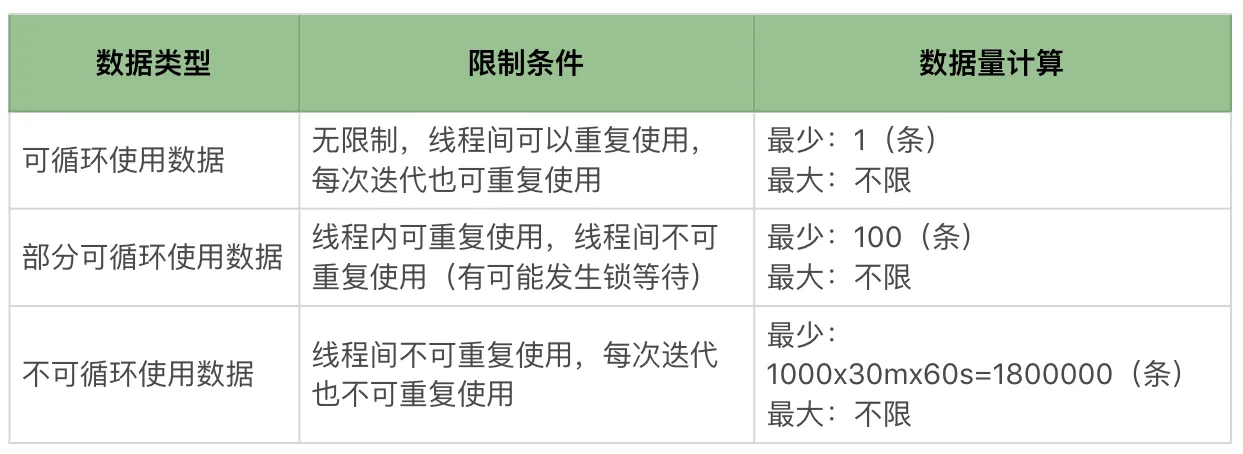
根据业务场景计算参数化数据量
场景一
当我们要模拟一天中的业务峰值时, "比如说,用户在早上登录系统之后,一直在系统中带着登录 session 做业务操作,并且不会退出,只有在下班时才退出系统。"
可以配置多少线程多少用户, 让每个线程在统一用户上循环执行, 即上文提到的部分可循环数据
Java
用户数据=线程个数场景二
模拟不同用户购买商品, 因此需要不同的用户账号
这就是不可循环使用的数据。在这样的场景中,就需要考虑场景的 TPS 和持续时间了。用户数据的计算方法是:
Java
tps x 持续时间(秒级)参数化数据来源
- 用户输入, 可以从库中采集
- 库里没有, 就得通过压力工具做参数化
总结
参数化时需要确保数据来源以保证数据的有效性,千万不能随便造数据。这类数据应该满足两个条件:
- 要满足生产环境中数据的分布;
- 要满足性能场景中数据量的要求