存储架构模式
参考: https://www.cnblogs.com/liconglong/p/16156453.html
数据库存储架构
读写分离
- 实现原理
- 数据库服务器搭建主从架构(通常一主二从)
- 主机负责读写, 从机只负责读
- 主机通过复制将数据同步到从机, 每台数据库服务器都存储了所有的业务数据
- 业务服务器将读写操作发给主机, 读操作发给从机
- 如何判断读写分离
- 业务量持续增长
- 先优化(索引, 缓存)再重构
- 复杂度分析
- 主从复制延迟
- 方法1: 读写绑定(不建议), 写操作后的读操作指定发给主机, 该方法业务侵入大, 且无法判断写和读的间隔
- 方法2: 二次读取(不建议), 读从机失败后再读一次主机, 该方法一是应用于新增操作, 更新操作不适用, 二是该方法如果有很多二次读取, 会大大增加主机压力
- 方法3: 业务分级(建议), 关键业务读写全部指向主机, 非关键业务采用读写分离, 注意开发方案(以及code review)要明确指向主机的地方, 避免编码人员偷懒全部读写主机
- 任务分解
- 主从复制延迟
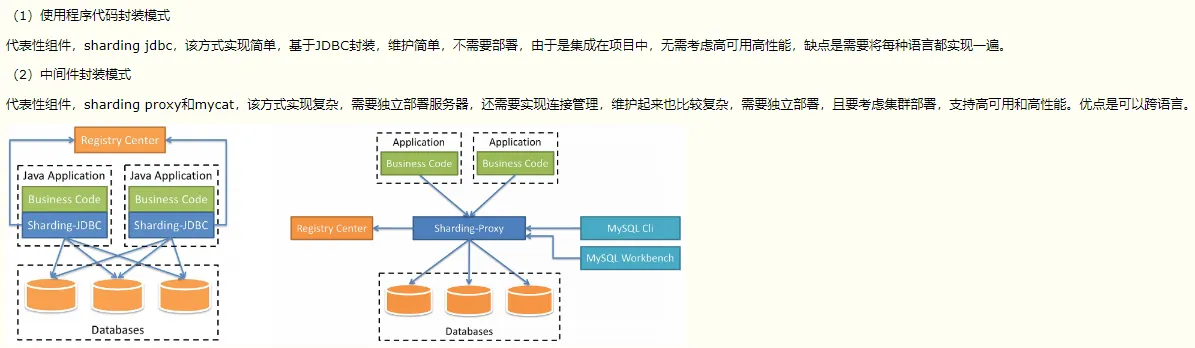
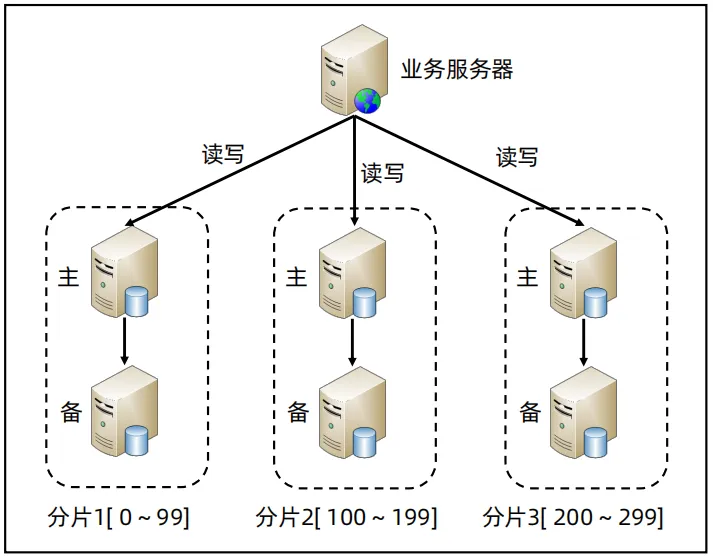
分库分表
- 在读写分离的场景下, 主机依然可能面临写入性能以及存储容量的瓶颈, 因此需要进行分库分表, 这里体现出的是叠加法则(加机器)
- 数据分库
- join问题, 原本在同一个库中的表分散到不同的库, 导致无法使用join查询
- 小表冗余, 如字典表
- 代码join, 代码里处理
- 字段冗余
- 事务问题, 需要使用分布式事务
- join问题, 原本在同一个库中的表分散到不同的库, 导致无法使用join查询
- 数据分表
- 垂直拆分: 按列拆分, 优化单机处理性能, 常见于2B领域超多列的表拆分
- 水平拆分: 按行拆分, 提升系统处理性能, 常见于2C领域超多行的表拆分
- 多大的表需要拆分?
- B+Tree的层数: 3层大约是2000万条
- Innodb buffer pool: 2000万条数据, 每条数据100字节, 单表就2G了
- 数据量预期会持续增长的表
- 分表复杂度在路由操作, count, join, orderby等操作, 一般不自己实现, 采用成熟的框架或开源中间件如sharding-JDBC
- 注意水平分表不能通过增加服务器来提升性能
- 服务器越多, 网络IO时间越长
- sharding-JDBC需要聚合结果, 性能是有瓶颈的
- mysql会连大量的sharing-JDBC, mysql的最佳连接数在50-100, 超过100性能会逐渐下降(也不要低于10)
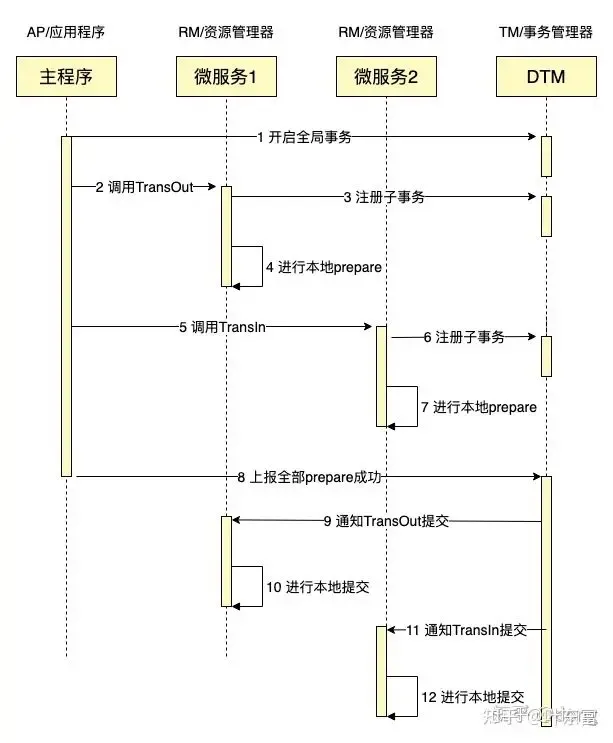
分布式事务
参考: https://www.cnblogs.com/liconglong/p/16277356.html
- 两阶段提交(一般用这个)
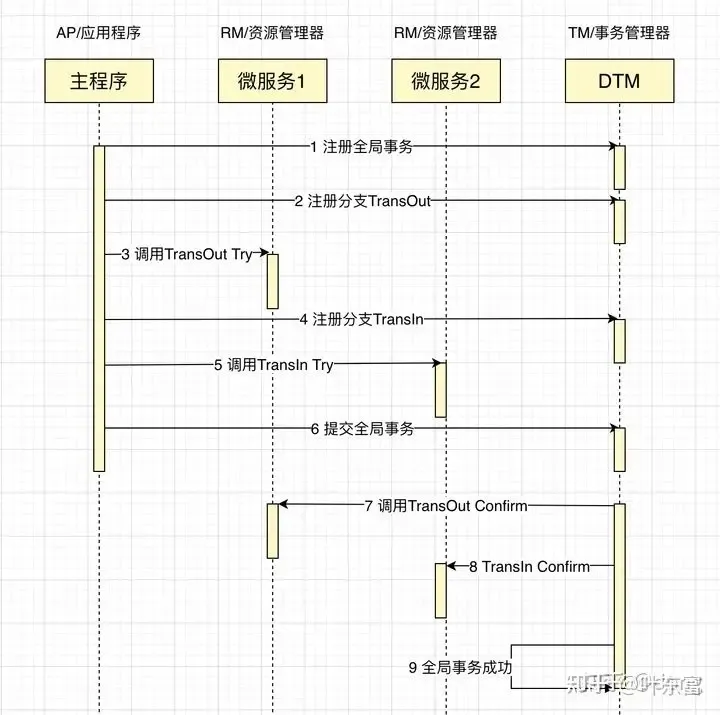
- 三阶段提交
复制架构
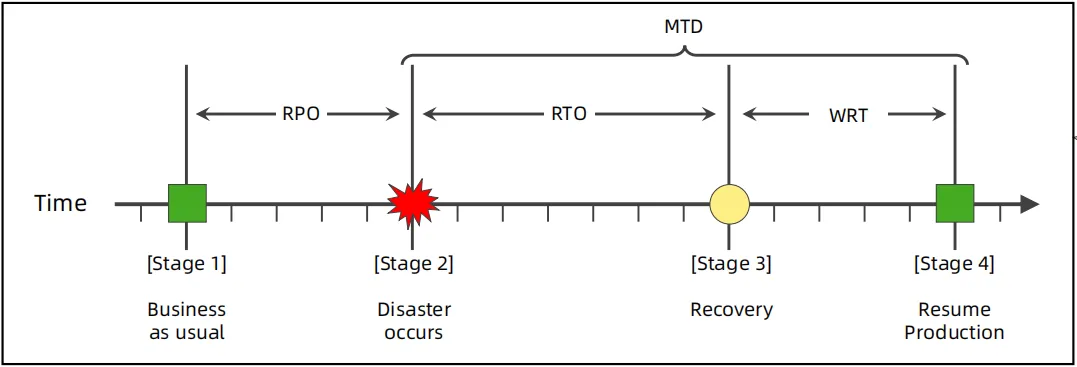
高可用关键指标
(一般使用PRO以及RTO)
- RPO:Recovery Point Objective,恢复点目标,指最大可接受的数据损失,因为数据备份和复制都需要时间,因此在发生故障时,会导致数据丢失。
- RTO:Recovery Time Objective,恢复时间目标,指最大可接受的系统恢复所需时间,这主要是因为问题的定位、处理、修复都是需要时间的。
- WRT:Work Recovery Time,工作恢复时间,指系统恢复正常后,恢复业务所需时间,因为要进行各种业务检查、校验、修复
- MTD:Maximum Tolerable Woentime,最大可容忍宕机时间,等于PTO + WRT
主备&主从架构
主备&主从
- 本质:主备复制的本质是通过冗余来提高可用性,而主从架构是通过冗余来提升读性能
- 变化:备机是否提供复制功能,备机部署地点、主备主从混合部署等
- 优点:实现简单,只需要数据复制,无状态检测和角色切换
- 缺点:需要人工干预,RTO比较大
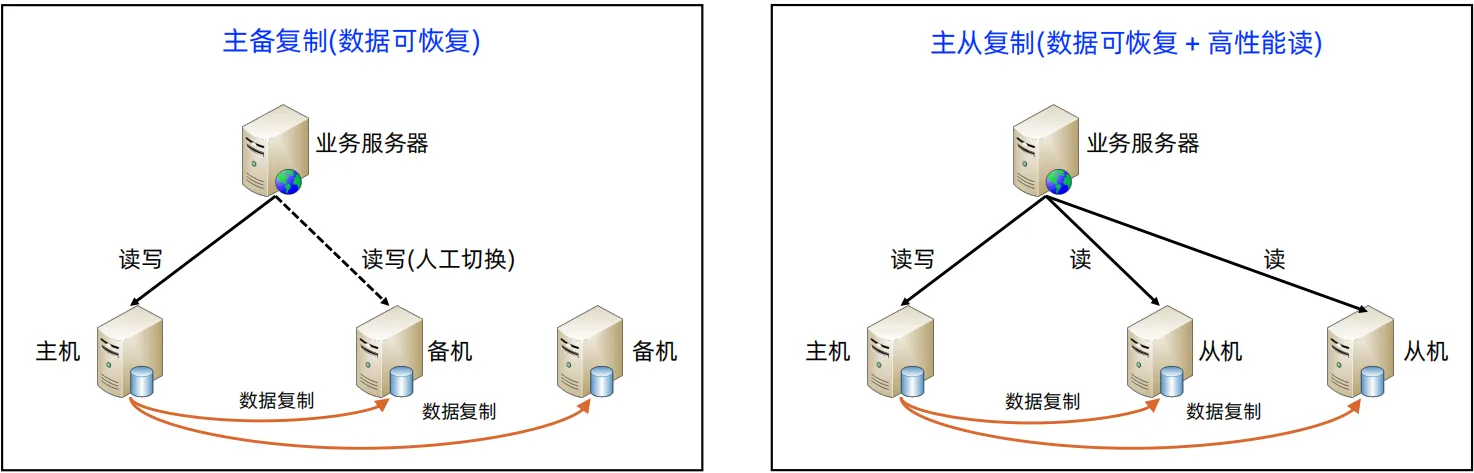
主备级联复制
- 是主备的一种变种,上面的主备是所有的从机都从主机中进行数据复制,在该方案中,备机一从主机进行数据复制,备机二从备机一中做数据复制。
- 变化:备机作为数据源
- 优点:主机故障后,切换备机一为主机,方便快捷,直接修改配置即可,无需修改备机二的配置,无需判断备机一和备机二的数据覆盖问题
- 缺点:备机一对于数据备份非常关键,备机一宕机会导致所有的备机都没有备份数据
- 应用:Mysql和Redis支持这种模式
- 这种模式只可以应用于主备架构,主从架构使用这种模式会导致更大的数据延迟
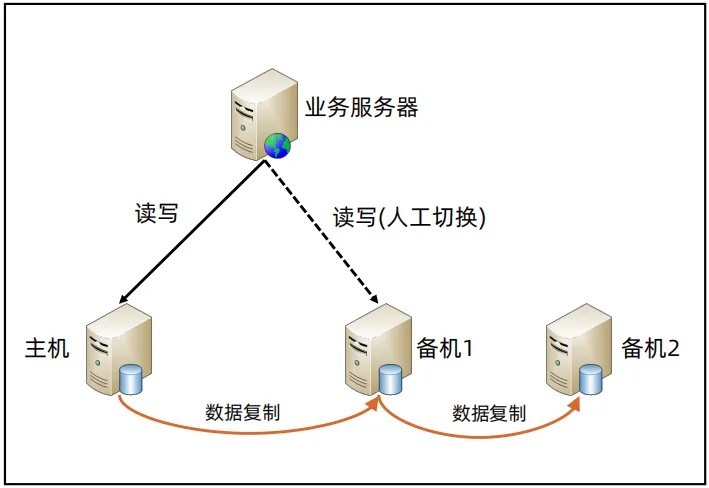
主备/主从架构的灾备部署
- 场景一:IDC-1 和 IDC-2在同一城市,可以应对机房级别的灾难;
- 场景二:IDC-1 和 IDC-2在不同城市,可以应对城市级别的灾难。
- 如果是主从架构的灾备,读从服务器只能从与主库在同一机房的从库中读,如果跨机房,读取数据的延迟会很高,另外就是两个机房间的数据备份也会比同机房的数据备份的延迟要高。
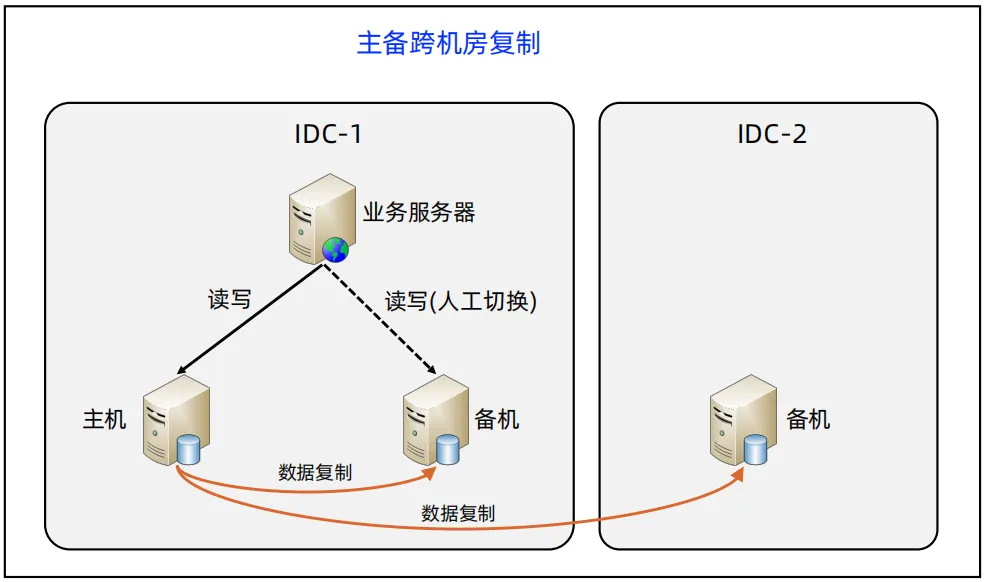
双机切换架构
- 下图显示的是主备切换
- 优点:可以自动实现故障切换,RTO短。
- 缺点:实现复杂,需要实现数据复制、状态检测、故障切换、数据冲突处理等
- 应用:主要用于内部系统、管理系统等数据变化不频繁、数据量不大的场景,这样发生切换后数据冲突的处理量会很小
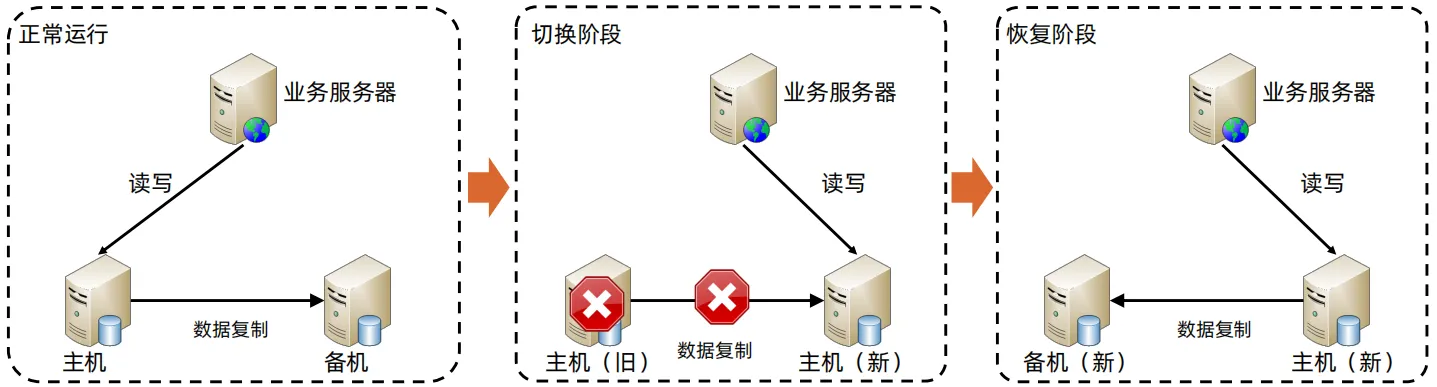
- 主从切换和主备切换非常类似,唯一不同的就是在切换阶段,只有主机对外提供读写服务,主机可能存在性能问题。
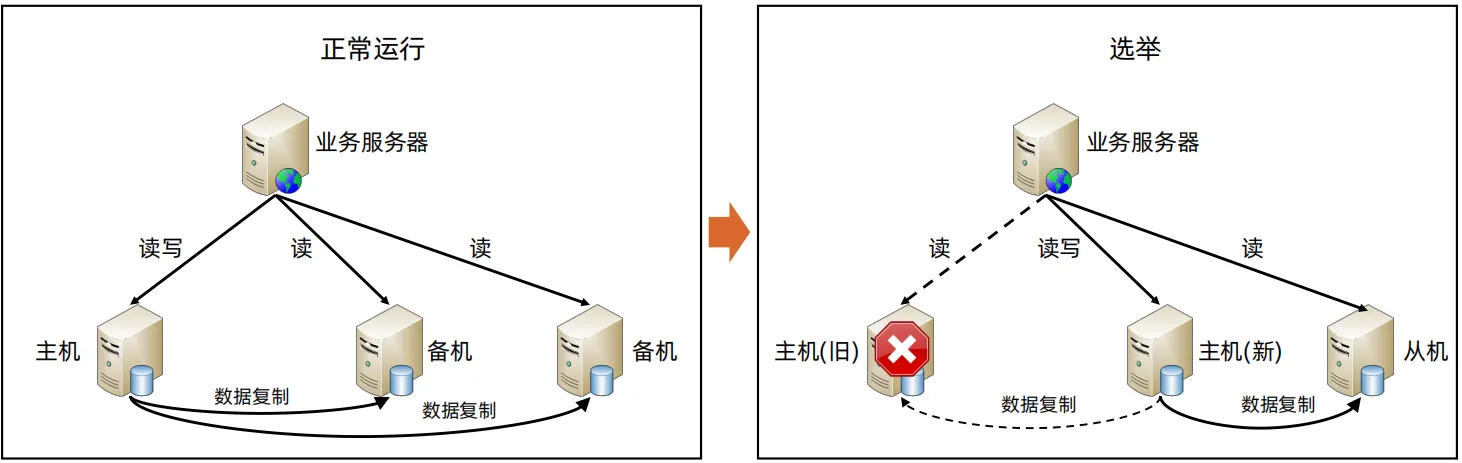
集群选举架构
- 主机发生故障后,集群通过选举的方式从多个从机中选择一个作为主机,然后其他从机从原来的主机上切换到新主机,从新主机上复制数据。
- 优点:可以自动实现故障恢复,PTO短,可用性更高
- 缺点:实现复杂,需要实现数据复制,状态检测、选举算法、故障切换、数据冲突等
- 应用:通用,例如Redis和MongoDB等
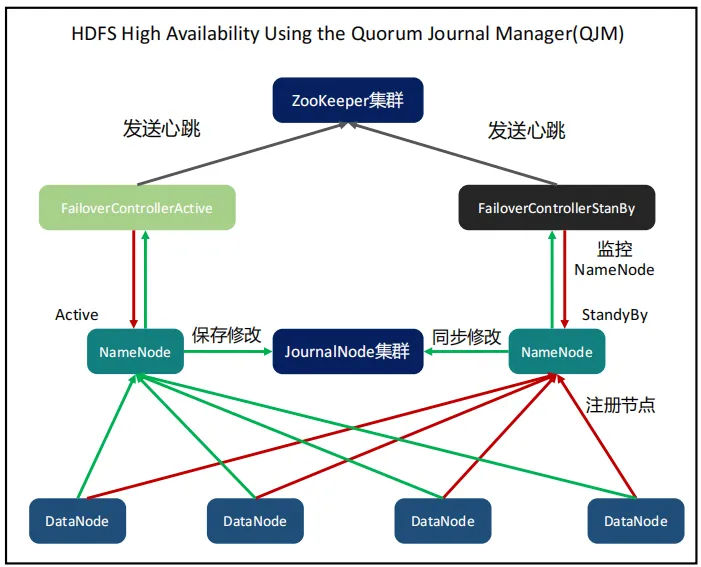
最佳实践:使用Zookeeper
- 如果我们自己要实现一个状态检测和集群选举,一般使用Zookeeper即可,基于Zookeeper来实现双机切换或集群选举,能够大大降低复杂度,因为Zookeeper本身已经保证了自己的高可用,且基于Zookeeper切换或选举过程实现比较简单,Zookeeper同时又很多其他的用途。
- 以HDFS集群为例,其就是基于Zookeeper实现NameNode的选举。
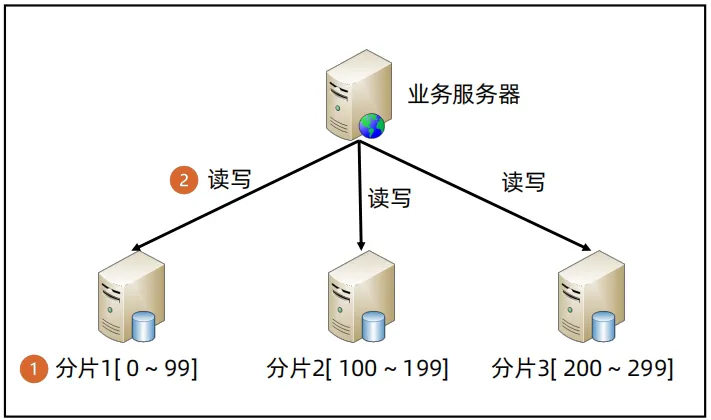
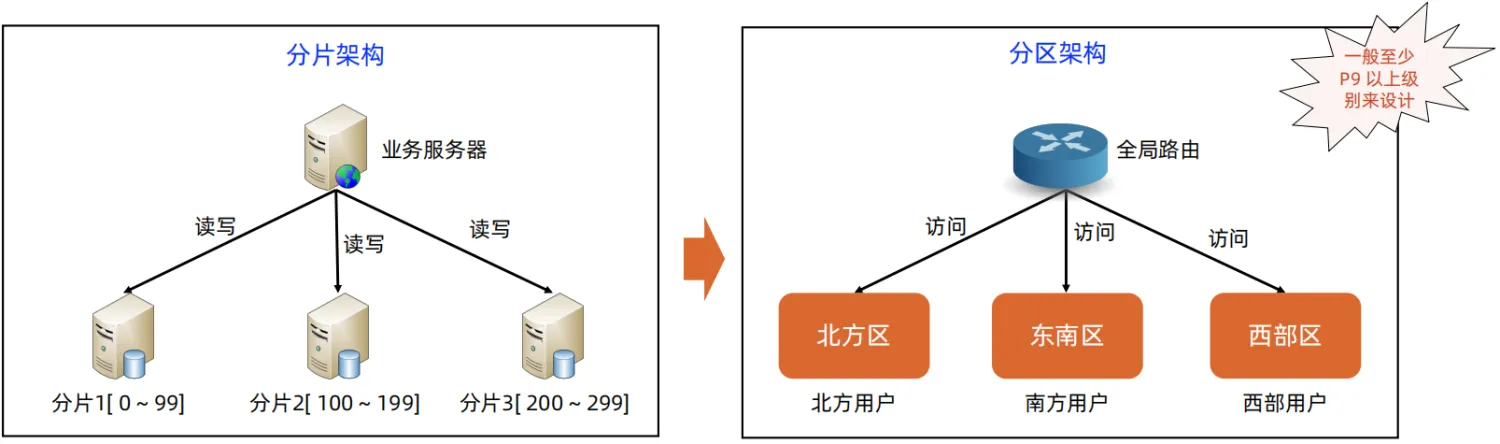
分片架构
- 分片架构的核心是通过叠加更多的服务器来提升写性能和存储性能。
- 在使用分片架构时,需要设计好分片规则和路由规则,分片规则即数据按照什么规则分片,路由规则指业务服务器如何找到数据。
分片规则
选取基数比较大的某个数据键值,让数据均匀分布,避免热点分片,基数是指被选数据维度的取值范围,均匀分布是指数据在取值范围内是均匀分布的,但是数据均匀分布不代表数据的读写是均匀分布的,例如常见的微博,大V和明星的数据访问量肯定比一般人的读流量要大的多。
常见的分片方式:主键分片、时间分片
- 主键分片:适合主业务数据,常见场景有用户ID、订单ID、Redis分片的Key、MongoDB的文档ID等
- 时间分片:适合流水型业务,例如创建日期,IoT事件、状态等。
常见分片规则:
- Hash分片:sharding key = hash(原键值) 最常见的是取模,例如使用订单号,按服务器数量分片,好处是分布均匀,不好的是不支持范围查询,另外一个是扩容非常麻烦,需要做数据迁移
- 范围分片:例如按照订单生成时间,每三个月做一个分片,这种方式分布不可能均匀,例如电商大促的时候,订单量是很大的。支持范围查询,优点是方便扩容新服务器,无需迁移历史数据
路由规则
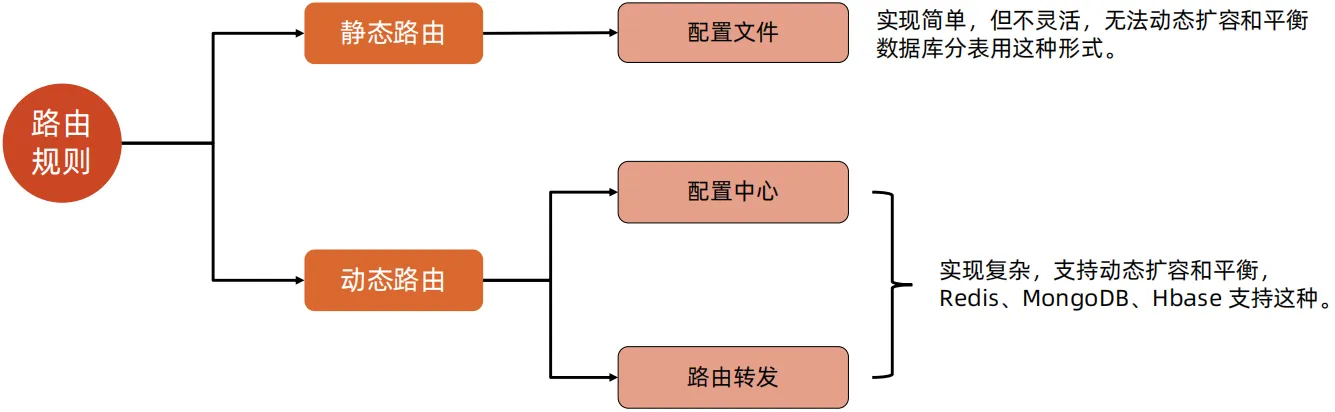 路由规则配置有静态路由或动态路由两种
路由规则配置有静态路由或动态路由两种
静态路由是指使用配置文件的方式,这种方式实现简单,但是不够灵活,无法动态扩容和平衡,数据库分表采用这种方式;
动态路由有使用配置中心和路由转发两种
配置中心的方式是有一个集中管理路由规则的配置中心;
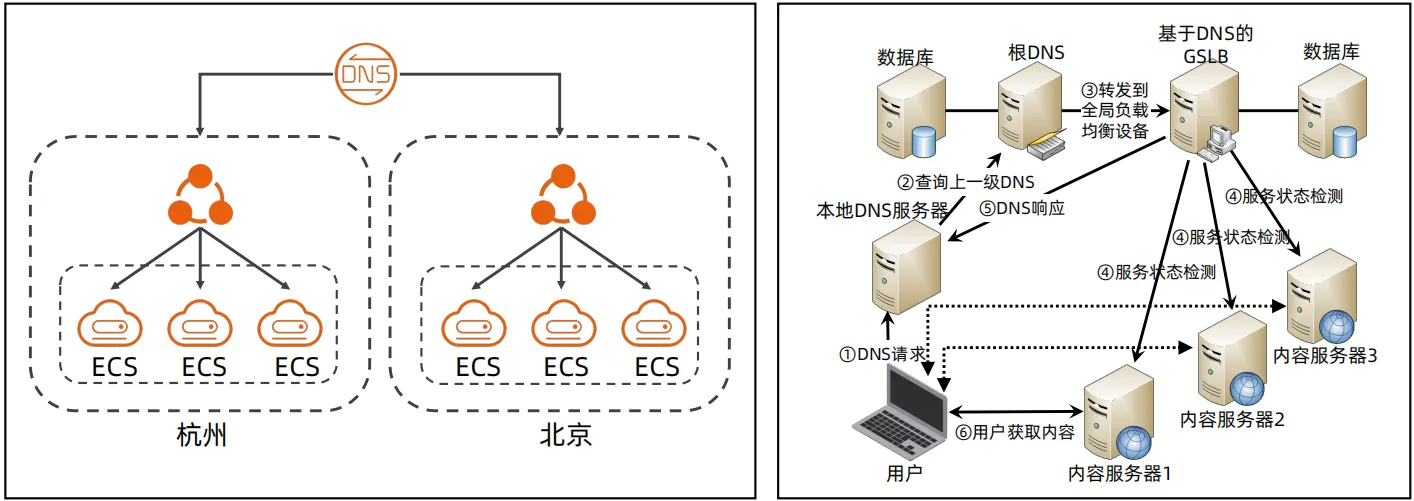
- 由专属的配置中心记录分片信息,客户端需要向配置中心查询分片信息,然后发起读写操作。以下图的MongoDB和HDFS为例,在MongoDB中,有一个Config Server的配置中心,应用客户端需要嵌入Router,首先Router从Config Server获取数据存储的分片,然后再指定分片进行查询;在HDFS中,有NameNode存储路由规则。
- 这种方式可以支持超大规模集群,集群数量可以达到几百上千,但是架构复杂,一般要求独立的配置中心节点,配置中心同时也需要高可用,例如MongoDB使用的是主备复制(replica set)来保证高可用、HDFS是使用的是Zookeeper保证的高可用(HDSF在2.0之前的Namenode是单点)
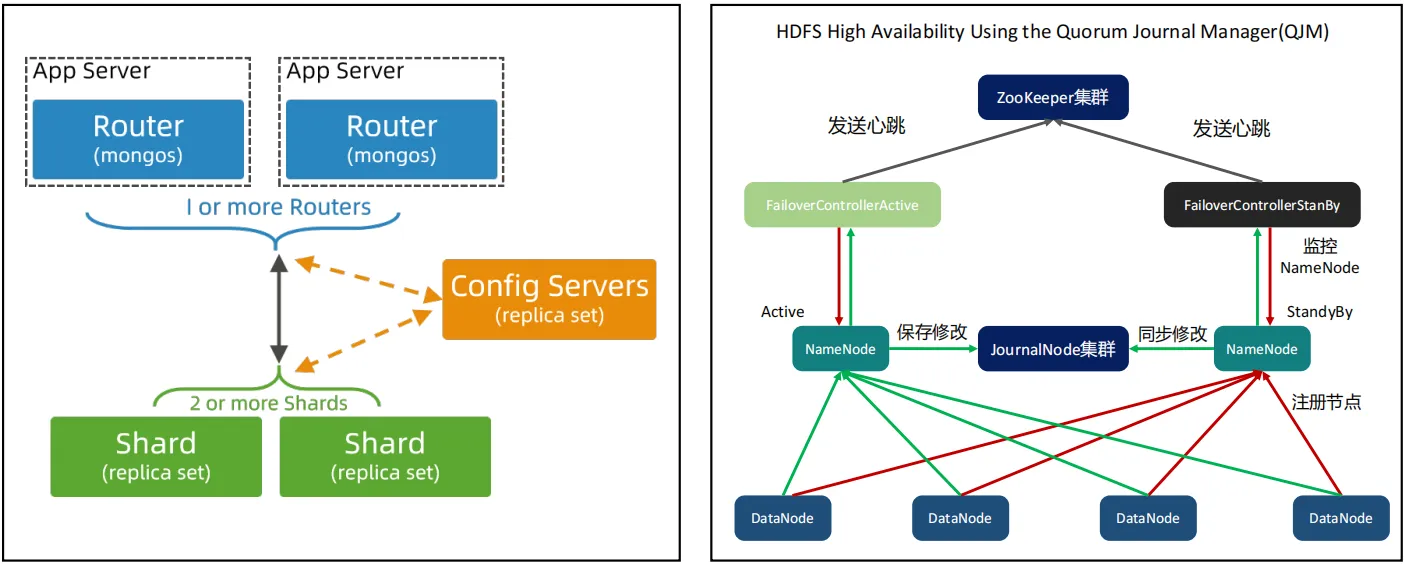
路由转发的方式并没有集中管理路由规则的配置中心,但是分片服务器知道各个分片服务器的数据存储情况,这种方式实现复杂,支持动态扩容和平衡,Redis、MongoDB、Hbase支持这种。
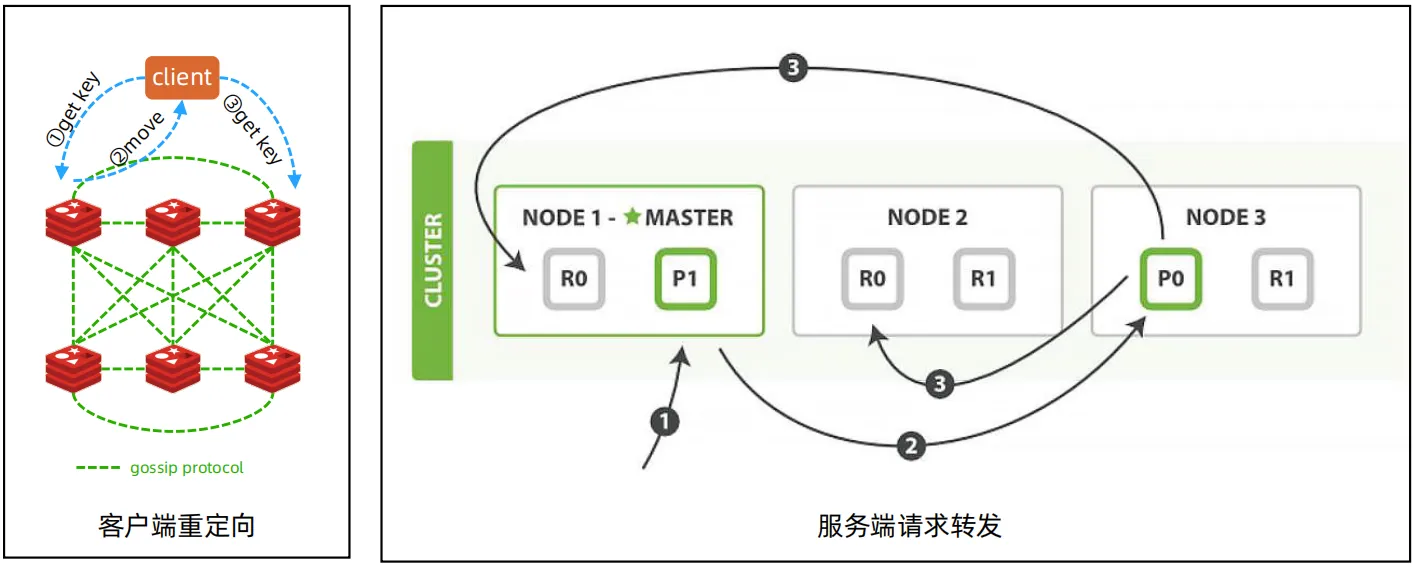
- 路由转发也有两种实现方式,客户端重定向和服务端请求转发。客户端重定向典型案例就是Redis,服务端请求转发的典型案例就是ElasticSearch
- 路由转发的方式是每个节点都保存所有路由信息,客户端请求任意节点即可,架构相对简单,以Redis的Cluster来说,通过gossip协议来实现分片信息更新,但是这种方式无法支持超大规模集群,以Redis为例,官方建议1000以内,因为集群数量过大,本身集群内节点的数据复制就会占用很大的带宽,会导致集群通讯问题。
那既然动态路由支持动态扩容和平衡,为什么数据库不适用这种方式呢,这是因为数据库对于ACID的要求非常高,比redis、MongoDB、HBase要高得多,因此其要实现动态路由的话,复杂度要高得多,因此数据库分表我们是不会使用动态路由的方式的。
高可用方案
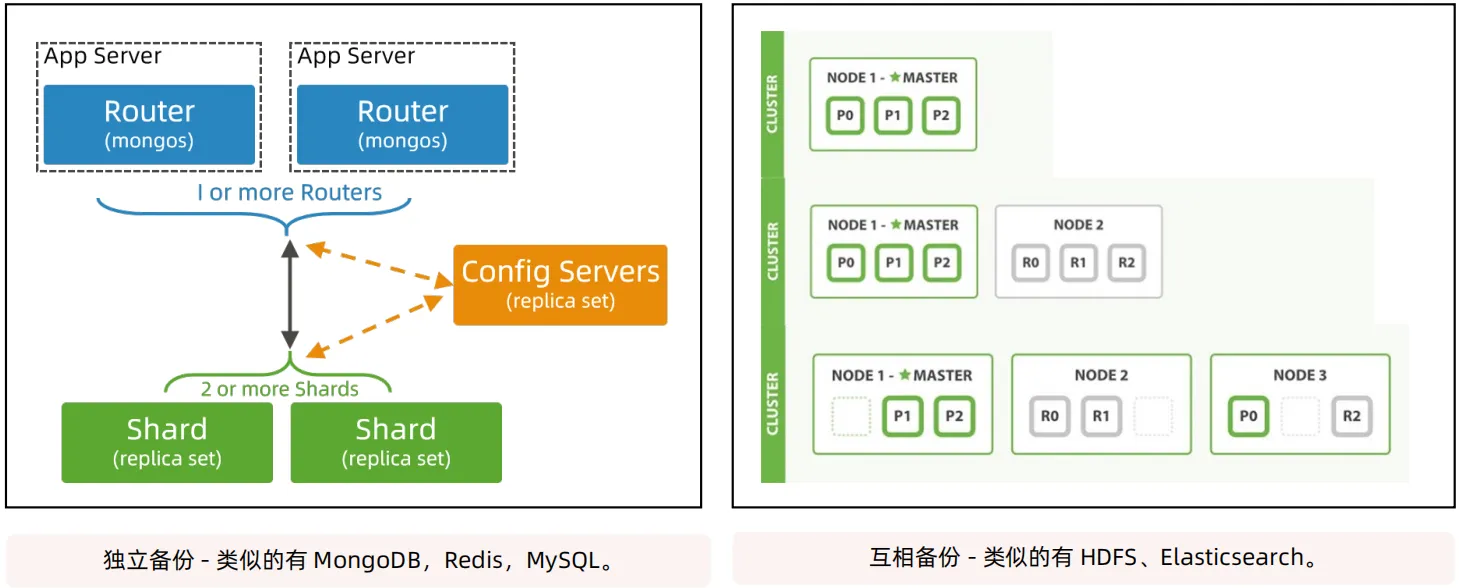
分片架构的高可用主要可以分为独立备份和相互备份。
- 独立备份:每个节点有独立的备份节点,可以用主备、主从、集群选举等方案实现;优点是实现简单,缺点是成本高,主要应用在存储系统已经支持节点级别复制的场景
- 互相备份:分片之间的节点相互备份,优点是成本低,缺点是实现复杂;主要应用在存储系统支持数据块级别的复制。
- 独立备份类似的应用场景有 MongoDB、Redis、Mysql等,互相备份类似的应用有 HDFS、Elasticsearch
分区架构
分片架构主要是为了提升写性能和解决存储限制的,但是其不能应对城市级别的故障,同时也不能应对大数据量远距离调用的性能问题,例如只部署在背景,那么大请求量的情况下,对于广州的用户来说,响应时间肯定会很长。
而分区架构就是为了解决上述两个问题,其通过冗余 IDC 来避免城市级别的灾难,并提供就近访问。如果应用分区架构,就说明业务量已经非常大了。
分片架构是不可以跨城市部署的,因为如果跨城市部署,分片架构的性能会急剧下降,就达不到分片架构提高集群性能的目的。
分区架构需要一个全局路由,将用户路由到不同的 IDC 进行访问,全局路由比较常见的是 DNS 和 GSLB,DNS 是标准协议,比较通用,但是其只能实现就近接入的路由; GSLB 非标准,需要独立开发和部署,功能非常强大,可以做状态检测、基于业务规则的定制路由。
分区架构备份策略常见的有:集中式、互备式、独立使
集中式:所有的 IDC 都用同一个 IDC 备份,设计简单,各分区之间无直接联系,可以做到互不影响;扩展也容易,如果要增加一个新的分区,只需要将新分区的数据复制到备份分区即可,其他的分区不受影响;缺点是成本较高,需要单独建一个备份中心。
互备式:所有的 IDC 之间数据互相备份,设计比较复杂,各个分区除了要承担业务数据存储,还需要成本备份功能,相互之间互相关联和影响;扩展也比较麻烦,例如要新增一个分区;优点是成本低,可以直接利用已有机房和网络。
独立式:每个分区都有自己的备份 IDC ,这种方式设计简单,各分区互不影响,扩展也容易,新增的分区只需要搭建自己的备份中心即可;缺点就是成本高,每个分区需要独立分备份中心,备份中心的场地、带宽、网络都是很高的成本。

在实际应用中,集中式用的比较多,因为其可扩展程度高,复杂度低,成本中等。